Options:
- # Session Start: Fri Jul 06 00:00:00 2007
- # Session Ident: #whatwg
- # [00:00] <rubys> this does look like the type of parser I was describing
- # [00:00] <rubys> Love the README. (Seriously)
- # [00:00] <hsivonen> good
- # [00:01] <hsivonen> well, it isn't runnable, yet
- # [00:02] * hsivonen checks in a more positive README
- # [00:02] <rubys> I wasn't being sarcastic, I was serious. I prefer truth in labeling over marketing any day.
- # [00:02] * Joins: wildcfo (n=wild_c_f@ool-44c1bb48.dyn.optonline.net)
- # [00:03] * Philip` 's tokeniser now works correctly on HTML documents that do not have any <, > or & in them
- # [00:04] <Philip`> (Well, it doesn't handle non-ASCII characters properly either)
- # [00:04] * rubys congratulates Philip`
- # [00:06] <othermaciej> Philip`: is your tokenizer "cat"?
- # [00:07] <Philip`> (Do the html5lib tokeniser tests intentionally omit the end-of-file token?)
- # [00:07] <hsivonen> Philip`: so it seems
- # [00:09] <jgraham> Philip`: End of file token is implied by "no more tokens". Is there some reason to make it explicit?
- # [00:09] * Joins: weinig (i=weinig@nat/apple/x-d6deb9efc6cd296d)
- # [00:09] <hsivonen> rubys: I'm committed to providing buffered (correct) SAX, true streaming (potentially incorrect in non-conforming cases) SAX, DOM and XOM support. dom4j support should come for free with DOM support. JDOM support should be easy once those are done. True streaming StAX is intentionally not a goal. Tree-buffered StAX will be possible but not my personal interest.
- # [00:10] <Philip`> othermaciej: It's about as useful as cat at the moment :-)
- # [00:11] <rubys> hsivonen: my only remaining concern is that it is a single person project. Communities tend to outlive individuals.
- # [00:11] <hsivonen> rubys: I welcome contributions under the same license.
- # [00:11] <Philip`> jgraham: I guess not, assuming there's no way to generate more tokens after the end-of-file token (which I think is true, but not entirely obvious)
- # [00:11] <rubys> but that's not a today concern, you've already addressed my bigger concerns.
- # [00:12] <Philip`> I just need to fix my token-stream-serialiser to omit the end-of-file one...
- # [00:12] <hsivonen> rubys: also, it seems to me that it is a good idea to have something that runs before building a community
- # [00:13] <rubys> hsivonen: I've have rather mixed experience with that: http://search.yahoo.com/search?p=%22good+ideas+and+bad+code+build+communities%2C+the+other+three+combinations+do+not%22
- # [00:13] <rubys> the best counter example I know of is Xalan.
- # [00:13] <rubys> Great code. Smart - very smart - developers. No community.
- # [00:14] <hsivonen> rubys: basically, my problem is that I don't know how to make the kind of commitments that I need to make in order to get paid for this and factor in the uncertainty (at this point) expectations of community
- # [00:16] <rubys> what commitments do you think html5lib has behind it? To my eyes, it has the exact right mix of good ideas and bad code (<smirk>) to be successful.
- # [00:17] <hsivonen> rubys: I've tried to be open about my plans, but I haven't published design docs, because I don't know if anyone would care to read them. I'd be happy to answer any questions on my design, though.
- # [00:17] <jgraham> All my bad code makes it successful? Excellent!
- # [00:17] <jgraham> (obviously rubys, anne and tbroyer are responsible for the good code)
- # [00:18] <hsivonen> rubys: as far as I can tell, html5lib is not on a paid basis in general
- # [00:30] * Philip` can tokenise start tags now, which is handy
- # [00:30] <hsivonen> rubys: I added some info to the wiki
- # [00:41] * Quits: tndH (i=Rob@83.100.252.160) ("ChatZilla 0.9.78.1-rdmsoft [XULRunner 1.8.0.9/2006120508]")
- # [00:50] <Philip`> This should, in theory, now do everything except doctypes...
- # [00:51] * Philip` tries to set it up to run actual tests
- # [00:51] * hsivonen reads Robert Burns' replies to jgraham
- # [00:53] * Philip` wonders if there's an easy way to parse JSON in C++
- # [00:54] <Philip`> Actually, that's kind of stupid, I'll just write a test wrapper in a proper language...
- # [00:54] * Quits: jgraham (n=jgraham@81-86-213-61.dsl.pipex.com) (Read error: 110 (Connection timed out))
- # [00:54] <hsivonen> Philip`: are the libs linked to from json.org unsatisfactory?
- # [00:55] <Philip`> I guess that'd work, but downloading and installing requires too much effort
- # [00:56] <Philip`> (and then reading the documentation to work out how to use them)
- # [00:56] <Philip`> (and then actually writing the code to use them, in C++)
- # [01:03] * Joins: jgraham (n=jgraham@81-86-222-150.dsl.pipex.com)
- # [01:05] <Philip`> Hmm, how are the ParseErrors in the tokeniser tests meant to work? They look like tokens, but it's not obvious where you add them so they don't conflict with all the other code that's fiddling with tokens...
- # [01:06] <hsivonen> Philip`: the tokenization spec is very clear about the sequence of parse errors relative to emitted tokens
- # [01:06] <hsivonen> Philip`: basically, you treat errors as an extra type of token
- # [01:06] <hsivonen> that the tokenizer emits
- # [01:08] <Philip`> Oh, I guess I just need to fix my concept of 'current token' so it's not simply the most recent token on the stack
- # [01:08] <hsivonen> Philip`: stack?
- # [01:09] <Philip`> Well, append-only stack
- # [01:09] <Philip`> so, er, I guess it's more like a list
- # [01:11] <hsivonen> Philip`: do you mean your test harness builds a list of tokens?
- # [01:11] <hsivonen> I was just thinking that there's no stack in the tokenizer
- # [01:13] <Philip`> The tokeniser itself builds a list of tokens (and then prints them all out at the end)
- # [01:13] <Philip`> (though I can change it to not do that, because it only ever needs a single current token and a bit of cheating to merge character tokens)
- # [01:19] * Quits: othermaciej (n=mjs@17.255.106.198)
- # [01:20] * Quits: billmason (n=billmaso@ip156.unival.com) (".")
- # [01:21] * Parts: zcorpan_ (n=zcorpan@84-216-41-39.sprayadsl.telenor.se)
- # [01:26] * Joins: othermaciej (n=mjs@17.255.106.198)
- # [01:27] <Philip`> Ooh, it sort of almost works, some of the time
- # [01:30] <Hixie> interesting, i never considered parse errors as a token type
- # [01:30] <Hixie> i just treat them as an out-of-band callback called during parse (my parser is synchronous, it returns a complete document once the parsing is done)
- # [01:33] <hsivonen> Hixie: I treat both errors and tokens as callbacks
- # [01:33] <Hixie> right
- # [01:33] <hsivonen> they are on different interfaces but the handler that generates JSON implements both
- # [01:35] <Philip`> Now I pass all of test1.dat and test2.dat except for about half of them which are just bits I haven't quite implemented yet
- # [01:35] * Quits: jgraham (n=jgraham@81-86-222-150.dsl.pipex.com) (Read error: 110 (Connection timed out))
- # [01:36] * Joins: aroben_ (n=adamrobe@17.255.105.112)
- # [01:37] * Philip` needs to write a Perl one after this
- # [01:42] * Joins: jgraham (n=jgraham@81-86-223-178.dsl.pipex.com)
- # [01:43] <Philip`> (Actually, I probably don't, since there'd be no point at all)
- # [01:43] <webben> why not?
- # [01:45] <Philip`> Because a tokeniser by itself isn't very useful :-)
- # [01:52] * Quits: aroben (n=adamrobe@17.203.15.248) (Connection timed out)
- # [01:55] * Joins: nikola_tesla (i=nagarjun@d60-65-150-197.col.wideopenwest.com)
- # [01:57] * Joins: Idiosyncronaut (i=nagarjun@d60-65-150-197.col.wideopenwest.com)
- # [01:57] * Quits: Idiosyncronaut (i=nagarjun@d60-65-150-197.col.wideopenwest.com) (Client Quit)
- # [01:58] * Joins: Idiosyncronaut (n=nagarjun@d60-65-150-197.col.wideopenwest.com)
- # [01:58] * Quits: nikola_tesla (i=nagarjun@d60-65-150-197.col.wideopenwest.com) (Nick collision from services.)
- # [02:01] * Quits: aroben_ (n=adamrobe@17.255.105.112) (Remote closed the connection)
- # [02:01] * Joins: aroben (n=adamrobe@17.255.105.112)
- # [02:02] * Joins: karlUshi (n=karl@dhcp-247-173.mag.keio.ac.jp)
- # [02:03] * Joins: yod (n=ot@softbank221018155222.bbtec.net)
- # [02:12] * Joins: nickshanks (n=nicholas@home.nickshanks.com)
- # [02:20] * Joins: jcgregorio (n=chatzill@209.79.152.140)
- # [02:27] * Quits: jcgregorio (n=chatzill@209.79.152.140) ("ChatZilla 0.9.78.1 [Firefox 2.0.0.4/2007060115]")
- # [02:28] * Joins: jcgregorio (n=chatzill@209.79.152.140)
- # [02:28] * Quits: jcgregorio (n=chatzill@209.79.152.140) (Remote closed the connection)
- # [02:29] * Quits: Idiosyncronaut (n=nagarjun@d60-65-150-197.col.wideopenwest.com)
- # [02:29] * Joins: jcgregorio (n=chatzill@209.79.152.140)
- # [02:30] * Quits: jcgregorio (n=chatzill@209.79.152.140) (Client Quit)
- # [02:36] * Joins: weinig_ (i=weinig@nat/apple/x-fd57ba0203b5a3b5)
- # [02:36] * Joins: billyjack (n=MikeSmit@eM60-254-213-214.pool.emobile.ad.jp)
- # [02:36] * Quits: MikeSmith (n=MikeSmit@eM60-254-197-94.pool.emobile.ad.jp) (Read error: 110 (Connection timed out))
- # [02:37] * Quits: weinig (i=weinig@nat/apple/x-d6deb9efc6cd296d) (Read error: 104 (Connection reset by peer))
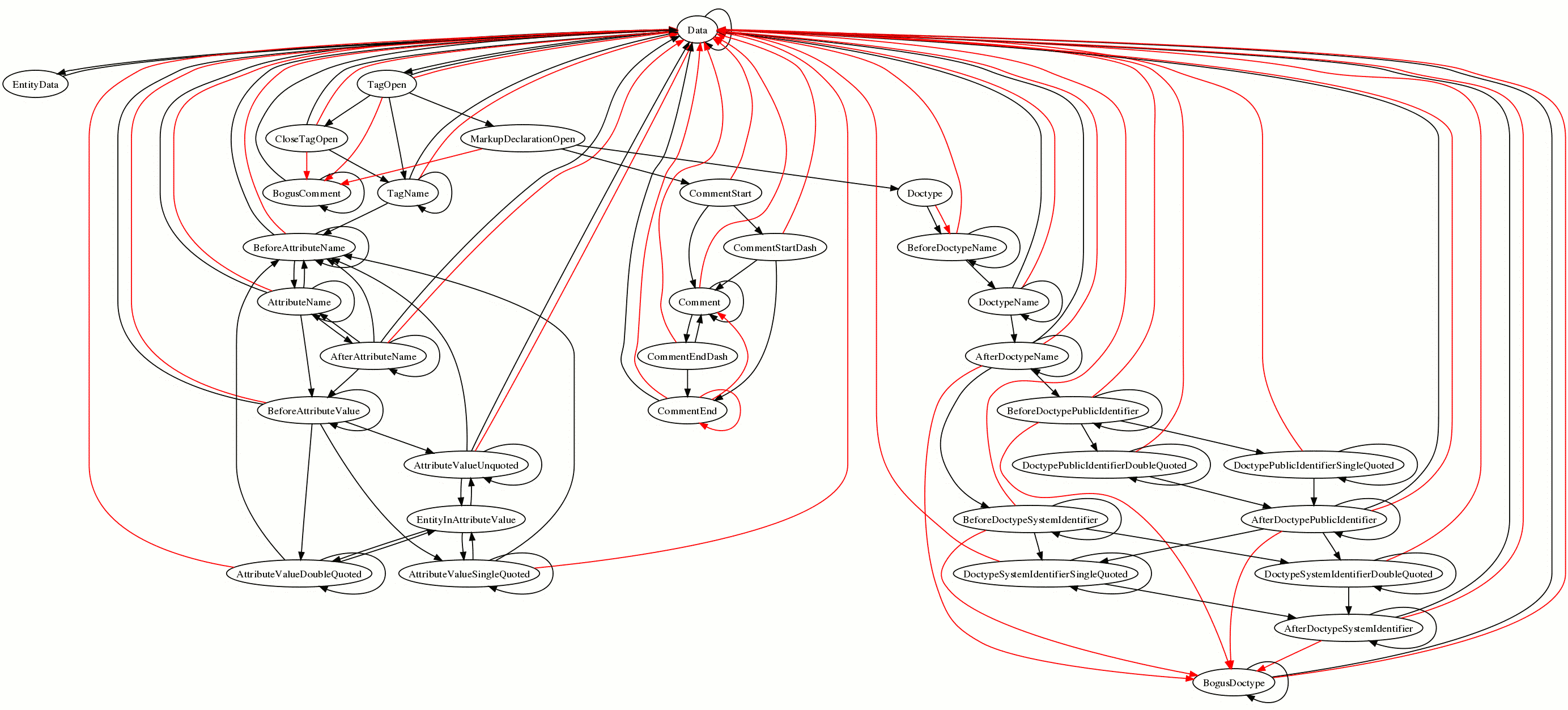
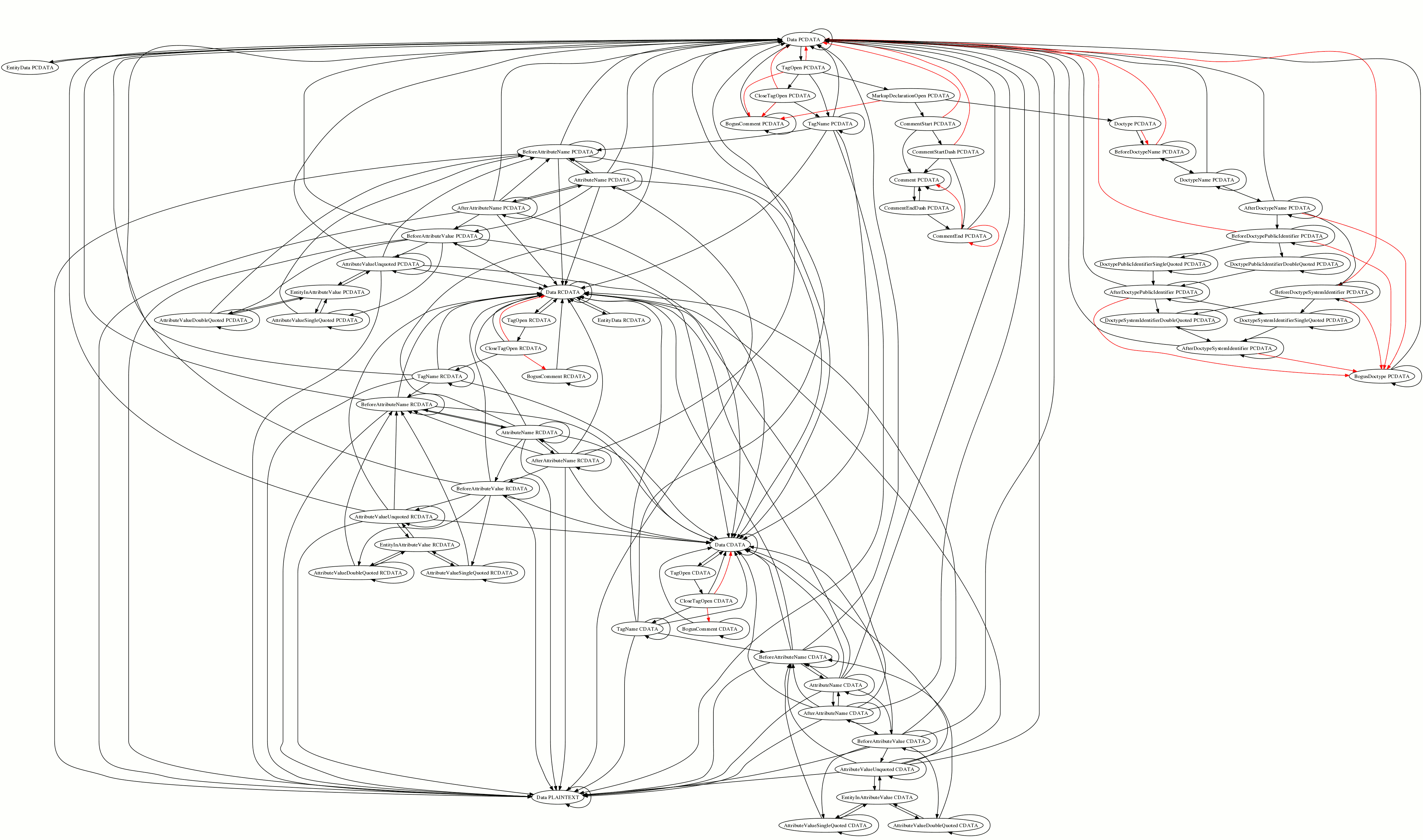
- # [02:38] <Philip`> http://canvex.lazyilluminati.com/misc/states6.png - now with fewer bugs than before, since implementation seems to pass most of the tests now
- # [02:39] <Philip`> *the implementation
- # [02:40] <nickshanks> yay squiggly lines
- # [02:41] <Lachy> Philip`: what's the difference between red and black lines?
- # [02:41] * Quits: bzed (n=bzed@dslb-084-059-100-221.pools.arcor-ip.net) ("Leaving")
- # [02:41] <Philip`> (Oh, I segfault on <x y="&">, which can't be good)
- # [02:42] <nickshanks> an especially squiggly red one going from CommentEndDash to Data
- # [02:42] <Philip`> Lachy: Red is transitions that are parse errors, black is transitions that probably aren't
- # [02:42] <Lachy> ok
- # [02:42] * Quits: webben (n=benh@91.84.193.157)
- # [02:42] <Philip`> ("probably" because of the parse-error-unless-it's-a-permitted-slash thing, which the graph treats as not-an-error)
- # [02:43] <Hixie> that's awesome
- # [02:43] <Hixie> why not have a red line and a black line when you have the permitted slash thing?
- # [02:43] <Hixie> you do that elsewhere
- # [02:43] <Hixie> yay, bogus doctype only has red arrows leading to it
- # [02:43] <Hixie> same with bogus comment, yay
- # [02:44] <Hixie> you really should use another colour for the EOF transitions
- # [02:44] <Hixie> in fact maybe we should have an EOF state
- # [02:44] <Hixie> instead of having EOF go back to the dat astate
- # [02:45] <Philip`> I can't easily have both because I only generate one arrow per transition from the original algorithm, and then delete all duplicates, so it only ends up with red+black when there are two separate transitions between the same states
- # [02:45] <Hixie> ah ok
- # [02:45] <Hixie> didn't realise it came from actual code
- # [02:46] <Hixie> that graph is awesome
- # [02:46] * Quits: hendry (n=hendry@kitten-x.com) ("leaving")
- # [02:46] <Philip`> It's not entirely actual code - the algorithm is represented as data in OCaml, and I can generate that graph or a C++ implementation from that data
- # [02:46] <Hixie> it shows that there are really three basic ideas
- # [02:46] <Hixie> aah
- # [02:46] <Hixie> cool
- # [02:47] <rubys> is there any reason why you couldn't generate a, say, Python or Ruby implementation from that data?
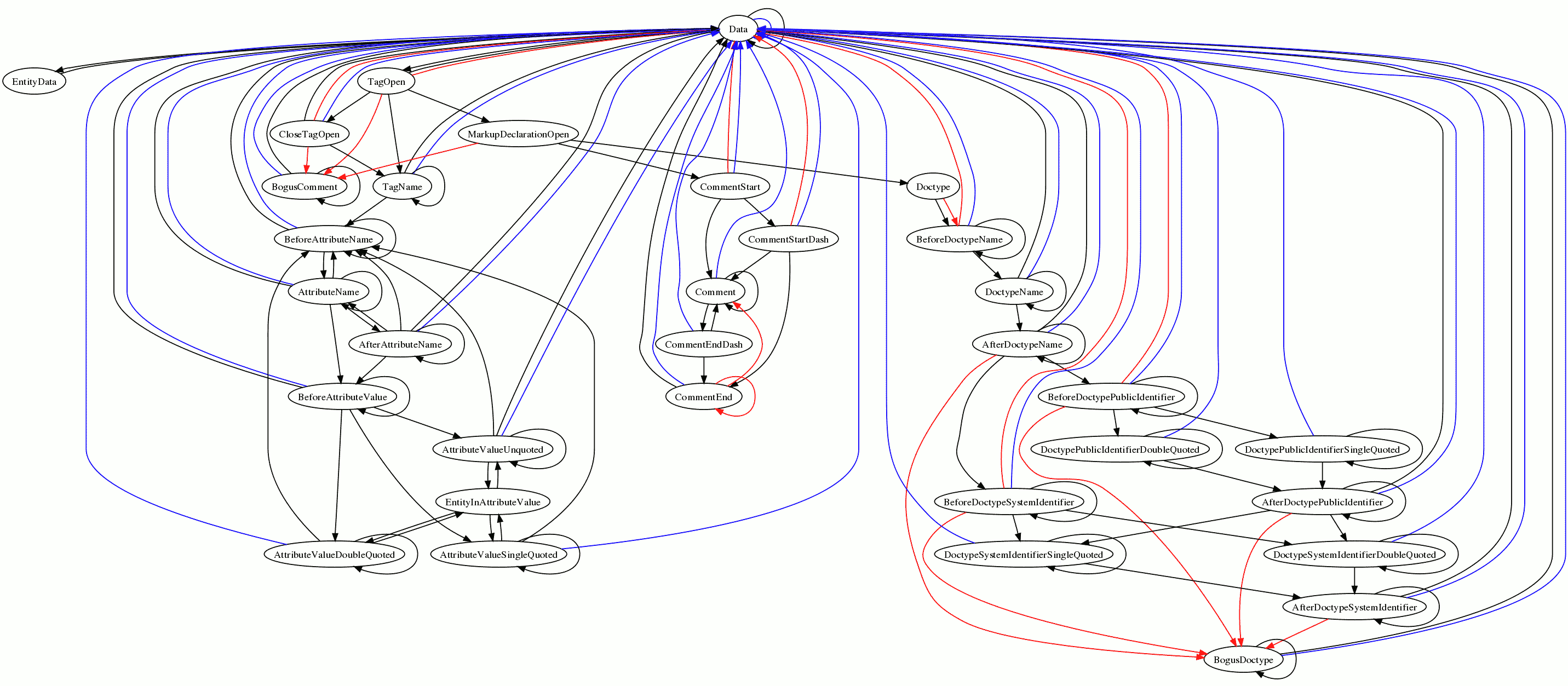
- # [02:50] <Philip`> http://canvex.lazyilluminati.com/misc/states7.png - unless I did something wrong, that has blue lines for every transition that cannot occur if EOF is never consumed
- # [02:50] <Philip`> (i.e. all the transitions that are (at least partially) caused by EOF)
- # [02:51] <Hixie> can you try it with a separate state for EOF? or is that more effort than it's worth?
- # [02:51] <Hixie> it'd be cool to have the arrows go down to another state for EOF, it would look less cluttered i'd think
- # [02:51] <Hixie> just an idea, don't worry about it if it's more work than a few seconds :-)
- # [02:51] <Philip`> rubys: I don't think there is any reason why that wouldn't work
- # [02:51] <Hixie> this is really cool
- # [02:52] * Quits: csarven (n=nevrasc@modemcable081.152-201-24.mc.videotron.ca) (Read error: 110 (Connection timed out))
- # [02:53] <Philip`> I've still had to manually write a few hundred lines of C++ (which would need to be ported to other languages), mostly for the entity parsing (since that's too boring to do in a more generic way), but then it generates a thousand lines of state-machine code automatically
- # [02:53] <rubys> I don't know O'Caml, but this sounds like a wonderful excuse to learn. Will you be publishing your source at some point?
- # [02:53] <Philip`> I didn't know it either, so I'm using it as exactly the same excuse ;-)
- # [02:54] <Philip`> I'll try to upload what I've done soonish
- # [02:54] <KevinMarks> looks like it could be used to generate code coverage testcases too
- # [02:55] <Philip`> I'm sure there must be a way to add in a new EOF state in about three lines of code, but I'm also sure they'll take a few minutes to work out...
- # [02:56] * Parts: rubys (n=rubys@cpe-075-182-064-252.nc.res.rr.com)
- # [02:56] * Joins: rubys (n=rubys@cpe-075-182-064-252.nc.res.rr.com)
- # [03:02] * Quits: weinig_ (i=weinig@nat/apple/x-fd57ba0203b5a3b5)
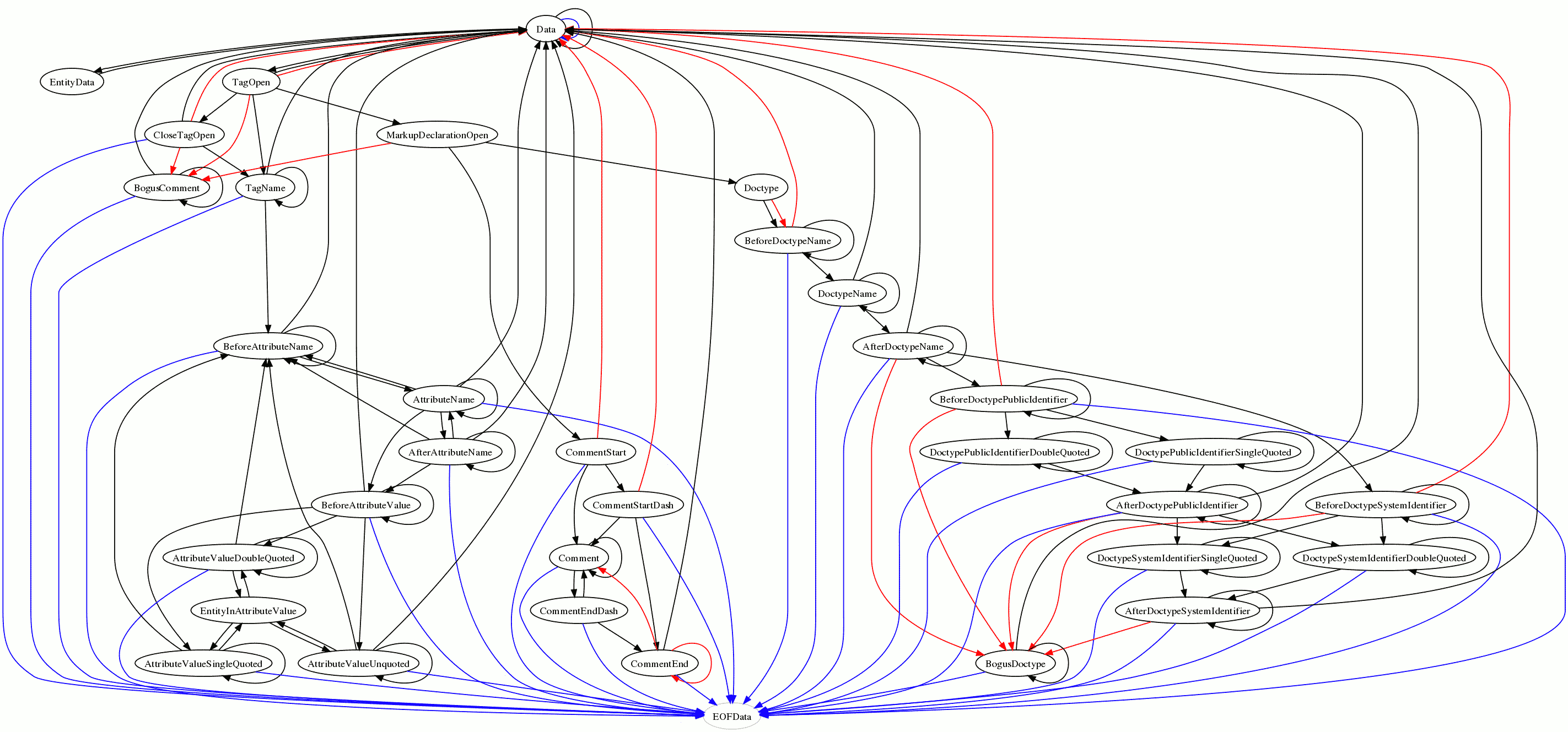
- # [03:03] <Philip`> http://canvex.lazyilluminati.com/misc/states8.png
- # [03:03] <Philip`> (Hmm, it took fourteen lines)
- # [03:04] <Hixie> sweet
- # [03:05] <Hixie> that's totally awesome
- # [03:06] <Philip`> Now I just need to make it able to generate the spec text from the algorithm ;-)
- # [03:06] <Hixie> hah
- # [03:06] * Quits: nickshanks (n=nicholas@home.nickshanks.com)
- # [03:08] * Philip` wonders if people have experience of how much more time it takes to implement tree construction compared to tokenisation
- # [03:08] <Hixie> about twice as long to write, about three times as long to debug, iirc
- # [03:08] <Hixie> but it's not especially hard
- # [03:08] <Hixie> just tedious
- # [03:09] * Quits: hober (n=ted@unaffiliated/hober) ("ERC Version 5.2 (IRC client for Emacs)")
- # [03:15] <rubys> why is there a blue arrow from data to data?
- # [03:19] <Philip`> Because I modified the algorithm so any case which is triggered by EOF and causes a transition into the Data state, was changed to transition into the EOFData state
- # [03:19] <Philip`> but the relevant part inside the Data state bit of the algorithm doesn't transition into the Data state
- # [03:20] <Philip`> (because I didn't bother writing in the "stay in the same state" bits explicitly)
- # [03:20] <Philip`> so that could be considered a bug in my old-algorithm-to-new-algorithm transformation code, but it'd require too much effort to fix :-)
- # [03:24] * Joins: csarven (n=nevrasc@modemcable081.152-201-24.mc.videotron.ca)
- # [03:26] <Philip`> Hmm, it's far too easy to get exponential growth in these things
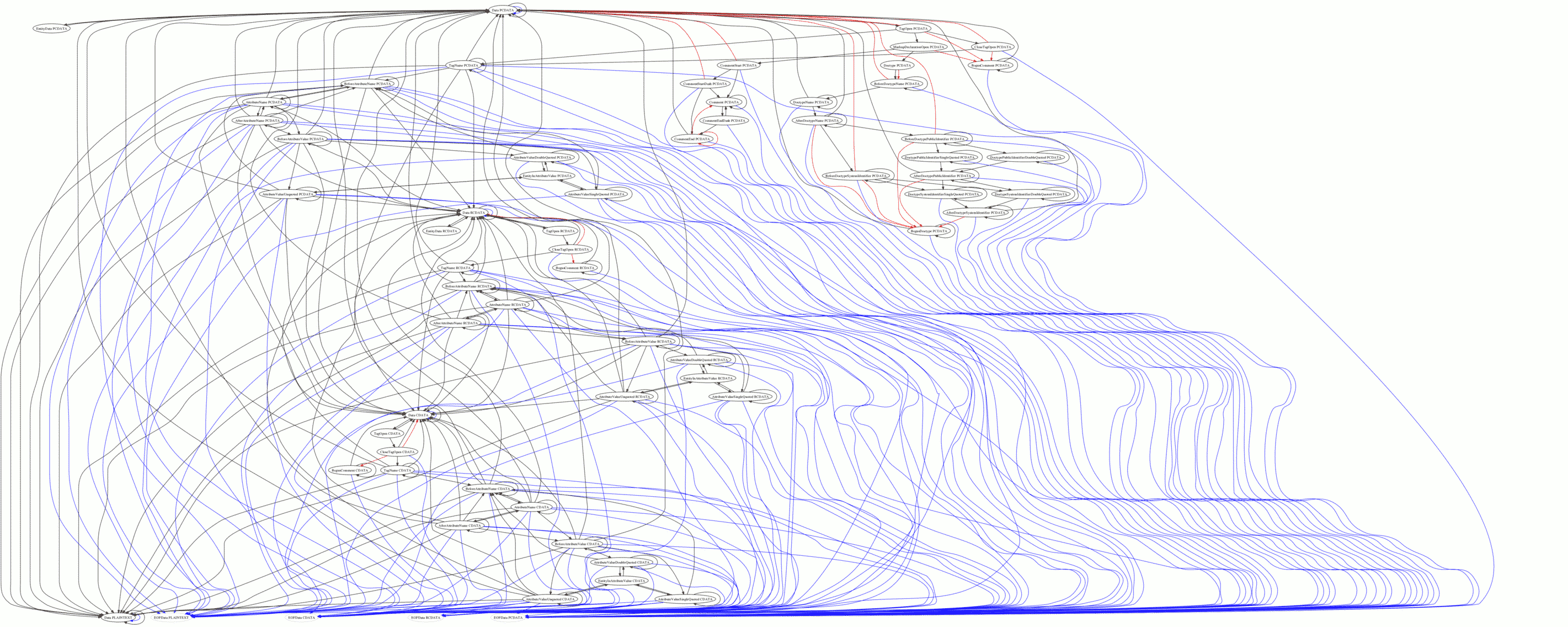
- # [03:28] <Philip`> http://canvex.lazyilluminati.com/misc/states9.png - I'm not sure why it's gone quite that bad
- # [03:29] <Hixie> holy crap what the hell is that
- # [03:29] <Hixie> states * pcdata etc?
- # [03:30] <Philip`> Yes
- # [03:31] <Philip`> I suppose it's unhappy because lots of states emit start/end tag tokens when they see EOF, and the tokeniser can't tell what the tree constructor is going to do to the content model flag when that happens, so I assume it could end up being set to anything, which causes unpleasant growth
- # [03:31] <Philip`> ("I assume" = "I tell the code to assume")
- # [03:34] <Philip`> Looks like that is the case - http://canvex.lazyilluminati.com/misc/states10.png is far better without the EOFs
- # [03:35] * Quits: KevinMarks (i=KevinMar@nat/google/x-3d39f747c7a64a31) ("The computer fell asleep")
- # [03:35] <Lachy> Philip`: what are you using to create those flow charts?
- # [03:36] <Philip`> Graphviz
- # [03:38] <Philip`> (It does tend to collapse into a mass of unreadable squiggles when you get past a certain size, and I always tend to use it on things that approach that size, but I've not heard of anything else that does the same kind of thing)
- # [03:39] <Philip`> (Uh, "same kind of thing" = drawing graphs, not collapsing into squiggles)
- # [03:40] * Quits: h3h (n=w3rd@66-162-32-234.static.twtelecom.net) ("|")
- # [03:40] * Joins: aroben_ (n=adamrobe@17.203.15.248)
- # [03:41] * Joins: weinig (i=weinig@nat/apple/x-e496eddb2ac3c796)
- # [03:48] * Quits: yod (n=ot@softbank221018155222.bbtec.net) ("Leaving")
- # [03:54] * Joins: minerale (i=achille@about/cooking/alfredo/Minerale)
- # [03:54] <minerale> What is whatwg ?
- # [03:55] <wildcfo> u mean this channel?
- # [03:55] <minerale> The website needs an 'about' link
- # [03:55] <minerale> I just saw the site in a slashdot sig, went there and was not sure how it related to silverlight
- # [03:56] * Quits: aroben (n=adamrobe@17.255.105.112) (Read error: 110 (Connection timed out))
- # [03:58] <minerale> is it some kind of social front end to w3c's html specifications?
- # [03:59] <Hixie> minerale: see http://blog.whatwg.org/faq/#whattf
- # [04:00] <Hixie> minerale: we're basically the renegade group that started html5
- # [04:01] * Joins: KevinMarks (n=KevinMar@user-64-9-232-168.googlewifi.com)
- # [04:05] <Philip`> My entirely unoptimised C++ tokeniser (which no longer segfaults) takes about 0.4 seconds for the HTML5 spec, which doesn't seem too bad
- # [04:07] <Philip`> (It's certainly a bit useless, because it just computes all the tokens and then memory-leaks them away)
- # [04:07] * Quits: Lachy (n=Lachy@203-158-59-119.dyn.iinet.net.au) (Read error: 110 (Connection timed out))
- # [04:10] * Parts: rubys (n=rubys@cpe-075-182-064-252.nc.res.rr.com)
- # [04:11] * aroben_ is now known as aroben
- # [04:20] <Hixie> Philip`: yeah tokenising is easy
- # [04:21] <Hixie> Philip`: the tree construction is definitely the more expensive part
- # [04:22] * Quits: KevinMarks (n=KevinMar@user-64-9-232-168.googlewifi.com) ("The computer fell asleep")
- # [04:28] * Joins: yod (n=ot@softbank221018155222.bbtec.net)
- # [04:32] * Quits: yod (n=ot@softbank221018155222.bbtec.net) (Client Quit)
- # [04:33] * Joins: yod (n=ot@softbank221018155222.bbtec.net)
- # [05:05] * Joins: Lachy (n=Lachy@124-168-30-161.dyn.iinet.net.au)
- # [05:05] * Joins: aroben_ (n=adamrobe@17.203.15.248)
- # [05:05] * Quits: aroben (n=adamrobe@17.203.15.248) (Read error: 104 (Connection reset by peer))
- # [05:16] * Quits: billyjack (n=MikeSmit@eM60-254-213-214.pool.emobile.ad.jp) ("Less talk, more pimp walk.")
- # [05:17] * Joins: weinig_ (i=weinig@nat/apple/x-beb99dddd700c698)
- # [05:17] * Quits: Lachy (n=Lachy@124-168-30-161.dyn.iinet.net.au) ("ChatZilla 0.9.78.1 [Firefox 2.0.0.4/2007051502]")
- # [05:18] * Quits: weinig (i=weinig@nat/apple/x-e496eddb2ac3c796) (Read error: 104 (Connection reset by peer))
- # [05:32] * Quits: dbaron (n=dbaron@corp-242.mountainview.mozilla.com) ("8403864 bytes have been tenured, next gc will be global.")
- # [05:35] * aroben_ is now known as aroben
- # [05:38] * Quits: aroben (n=adamrobe@17.203.15.248)
- # [06:00] * Quits: weinig_ (i=weinig@nat/apple/x-beb99dddd700c698)
- # [06:22] * Joins: weinig (n=weinig@c-67-188-89-242.hsd1.ca.comcast.net)
- # [06:22] * Quits: csarven (n=nevrasc@modemcable081.152-201-24.mc.videotron.ca) ("http:/www.csarven.ca")
- # [06:23] * Quits: weinig (n=weinig@c-67-188-89-242.hsd1.ca.comcast.net) (Remote closed the connection)
- # [06:24] * Joins: weinig (n=weinig@c-67-188-89-242.hsd1.ca.comcast.net)
- # [06:24] * Quits: weinig (n=weinig@c-67-188-89-242.hsd1.ca.comcast.net) (Remote closed the connection)
- # [06:26] * Joins: weinig (n=weinig@c-67-188-89-242.hsd1.ca.comcast.net)
- # [06:42] * Joins: aroben (n=adamrobe@c-67-160-250-192.hsd1.ca.comcast.net)
- # [06:57] * Quits: weinig (n=weinig@c-67-188-89-242.hsd1.ca.comcast.net) (Remote closed the connection)
- # [06:58] * Joins: weinig (n=weinig@c-67-188-89-242.hsd1.ca.comcast.net)
- # [07:34] * Quits: aroben (n=adamrobe@c-67-160-250-192.hsd1.ca.comcast.net) (Remote closed the connection)
- # [07:35] * Joins: aroben (n=adamrobe@c-67-160-250-192.hsd1.ca.comcast.net)
- # [07:41] * Quits: dolphinling (n=chatzill@rbpool1-86.shoreham.net) (Read error: 110 (Connection timed out))
- # [08:01] * Joins: MikeSmith (n=MikeSmit@eM60-254-198-58.pool.emobile.ad.jp)
- # [08:05] * Quits: yod (n=ot@softbank221018155222.bbtec.net) (Remote closed the connection)
- # [08:06] * Joins: yod (n=ot@softbank221018155222.bbtec.net)
- # [08:16] * Joins: webben (n=benh@91.84.193.157)
- # [08:35] * Quits: webben (n=benh@91.84.193.157) (Read error: 110 (Connection timed out))
- # [08:54] <Hixie> http://html5.googlecode.com/svn/trunk/data/
- # [08:54] <Hixie> enjoy
- # [08:55] <Hixie> (hsivonen, jgraham, Philip`, anyone else writing an HTML5 parser ^)
- # [09:04] * Quits: wildcfo (n=wild_c_f@ool-44c1bb48.dyn.optonline.net) ("This computer has gone to sleep")
- # [09:10] * Quits: duryodhan (n=chatzill@221.128.138.137) (Read error: 110 (Connection timed out))
- # [09:12] * Quits: weinig (n=weinig@c-67-188-89-242.hsd1.ca.comcast.net)
- # [09:27] * Joins: KevinMarks (n=KevinMar@c-76-102-254-252.hsd1.ca.comcast.net)
- # [09:30] * Joins: tndH (i=Rob@83.100.252.160)
- # [09:32] * Quits: karlUshi (n=karl@dhcp-247-173.mag.keio.ac.jp) ("Where dwelt Ymir, or wherein did he find sustenance?")
- # [09:36] <hsivonen> Hixie: thank you
- # [09:40] <Hixie> hm
- # [09:40] <Hixie> so i have data on attributes-per-element and suchlike
- # [09:40] <Hixie> but i don't know exactly what you want to know
- # [09:41] <hsivonen> cumulative percentages of x% had 0 attributes, y% had <=1 attributes, z% had <=2 attributes, etc.
- # [09:41] <Hixie> hm
- # [09:43] * Quits: yod (n=ot@softbank221018155222.bbtec.net) ("Leaving")
- # [09:44] <Hixie> hm
- # [09:44] <Hixie> if 10 elements had 0 attributes
- # [09:44] <Hixie> and i know there were 20 elements
- # [09:44] <Hixie> and 5 elements had 1 attribute
- # [09:44] <hsivonen> I meant element instances, not element names, btw
- # [09:45] <Hixie> that means 75% had <= 1
- # [09:45] <Hixie> right?
- # [09:45] <Hixie> yeah
- # [09:45] <Hixie> i know
- # [09:45] <hsivonen> yes
- # [09:45] <Hixie> so i just need to add numbers until i get to one where i don't know the number
- # [09:46] * Quits: othermaciej (n=mjs@17.255.106.198)
- # [09:48] * Joins: othermaciej (n=mjs@17.255.106.198)
- # [09:55] * Joins: wildcfo (n=wild_c_f@ool-44c1bb48.dyn.optonline.net)
- # [10:13] * Joins: zcorpan_ (n=zcorpan@84-216-41-227.sprayadsl.telenor.se)
- # [10:19] * Joins: maikmerten (n=maikmert@T72ea.t.pppool.de)
- # [10:20] <Hixie> hsivonen: ok, see http://html5.googlecode.com/svn/trunk/data/misc.txt
- # [10:24] <hsivonen> Hixie: thank you
- # [10:25] <Hixie> my pleasure
- # [10:25] <hsivonen> elements with <= 0 attributes: 33.5% is lower than I would have guessed
- # [10:26] <Hixie> most documents consist primarily of <td>s with bgcolors, <font>s, and such like
- # [10:27] <hsivonen> I had guessed that 3 attributes is the common case. not such a bad guess
- # [10:28] <hsivonen> I readjust my guess to 5
- # [10:28] <Hixie> amusingly, the more documents i scan, the greater the portion that is XHTML
- # [10:29] <Hixie> in a sample of several dozen billion documents, it was about 0.2%, vs 0.02% for a sample of only a few billion (smaller sample being biased towards western pages with higher page rank)
- # [10:30] <Hixie> (0.2% is vs 97.5% for text/html)
- # [10:32] * Joins: ROBOd (n=robod@86.34.246.154)
- # [10:32] * Joins: BenWard (i=BenWard@nat/yahoo/x-0679d5280a2ae34b)
- # [10:37] <hsivonen> Hixie: testing whether the stack has "table" in table scope is the same as checking whether there's a "table" on the stack at all, right?
- # [10:38] <zcorpan_> Hixie: did you find anything with <! ">" > ?
- # [10:38] <Hixie> zcorpan_: didn't have a chance to look into that yet
- # [10:38] <zcorpan_> ok
- # [10:38] <Hixie> zcorpan_: but the fact that only IE does it makes me think it's not a big deal
- # [10:38] <Hixie> hsivonen: um
- # [10:39] <Hixie> hsivonen: yeah, i guess so
- # [10:39] <hsivonen> Hixie: ok. thanks
- # [10:39] <Hixie> does the spec ever ask that?
- # [10:41] <hsivonen> Hixie: yes
- # [10:41] <hsivonen> Hixie: I sent email
- # [10:41] <Hixie> k
- # [10:43] <othermaciej> Hixie: so obviously XHTML lowers your pagerank!
- # [10:43] <othermaciej> evil google conspiracy!
- # [10:43] * Quits: wildcfo (n=wild_c_f@ool-44c1bb48.dyn.optonline.net) ("This computer has gone to sleep")
- # [10:43] <Hixie> othermaciej: lol
- # [10:43] <Hixie> i wouldn't be surprised if that was actually true
- # [10:44] <Hixie> i don't think google really supports xhtml
- # [10:44] <Hixie> we probably treat it as text/html and get all confused or something
- # [10:45] <zcorpan_> like mobiles?
- # [10:45] <zcorpan_> :)
- # [10:51] <Hixie> yeah, probably
- # [10:58] * Quits: aroben (n=adamrobe@c-67-160-250-192.hsd1.ca.comcast.net)
- # [11:01] <hsivonen> Hixie: according to markp and Matt Cutts on rubys' blog, the XHTML non-support is changing
- # [11:06] <hsivonen> hmm. actually, neither of them said anything about Google parsing XHTML right...
- # [11:09] <othermaciej> I wonder how much of the nominal html on the web is mobile-targeted (and therefore not really parsed as xhtml)
- # [11:12] * Joins: bzed (n=bzed@dslb-084-059-113-101.pools.arcor-ip.net)
- # [11:18] * Joins: duryodhan (n=chatzill@221.128.139.94)
- # [11:37] <zcorpan_> othermaciej: btw, did you debug why dom2string hit a "Maximum call stack size exeeded" error in webkit?
- # [11:39] <othermaciej> zcorpan_: haven't had time so far
- # [11:39] <othermaciej> zcorpan_: can you remind me of the relevant URL?
- # [11:39] <othermaciej> I can try it now
- # [11:42] <zcorpan_> othermaciej: http://simon.html5.org/temp/html5lib-tests/
- # [11:46] <othermaciej> zcorpan_: thanks
- # [11:50] <gsnedders> does any HTML5 document meet the nesting requirements once parsed?
- # [11:51] <zcorpan_> gsnedders: what nesting requirement?
- # [11:52] <gsnedders> zcorpan_: things like <div>test<p>test</p></div>
- # [11:52] <hsivonen> gsnedders: yes.
- # [11:52] <gsnedders> like, the content model (I say remembering the name)
- # [11:52] <zcorpan_> gsnedders: oh. no.
- # [11:52] <hsivonen> gsnedders: no
- # [11:53] <zcorpan_> gsnedders: any stream of characters results in a tree. but it might not conform to the content model rules
- # [11:54] <gsnedders> I'm just thinking about how plausible it'd be to take arbitrary input and output (machine-checkable) conformant HTML5
- # [11:56] <hsivonen> gsnedders: you'd probably need methods similar to what John Cowan's TagSoup uses
- # [11:56] <hsivonen> gsnedders: the HTML5 parsing algorithm itself specifically is not about doing that
- # [11:56] <gsnedders> hsivonen: I know. I was just wondering how much it does do in itself.
- # [11:56] <othermaciej> even things that parse without parse errors could result in a non-conforming document
- # [11:57] <zcorpan_> gsnedders: it builds a tree
- # [11:57] <hsivonen> gsnedders: it makes sure that tables don't have intervening cruft and it moves stuff between head and body to head
- # [11:57] <gsnedders> My issue was really as to how close to being conforming the output of it was, and whether what it did change made those sections conforming
- # [11:58] <othermaciej> I wonder if all the machine-checkable conformance criteria are practically machine-fixable
- # [11:58] <gsnedders> othermaciej: invalid dates won't be.
- # [11:58] <gsnedders> (short of dropping them)
- # [11:59] <hsivonen> othermaciej: everything that is machine-checkable is machine-fixable to the point that the machine checker doesn't know the difference (but the result can be totally bogus)
- # [11:59] <zcorpan_> <title>s in body are still moved to head too, right?
- # [11:59] <othermaciej> you could use an ultra-lenient best-guess date parser
- # [11:59] <hsivonen> case in point: filling alt attributes with junk
- # [11:59] <gsnedders> othermaciej: even that will have limitations.
- # [11:59] <hsivonen> or copying src to longdesc to please an accessibility checker
- # [12:00] <othermaciej> whether an alt attribute is junk isn't machine-checkable, really
- # [12:00] <hsivonen> othermaciej: that's my point
- # [12:00] <othermaciej> it might be than an image is a picture of the text "asdfjkl; i hate conformance checking"
- # [12:00] <othermaciej> and so that would be totally valid alt text
- # [12:01] <hsivonen> so anything that is non-conforming in a machine-checkable way can be replaced with stuff that is semantically junk but that is syntactically ok
- # [12:01] <othermaciej> I guess it depends on how you want to fix things
- # [12:02] <othermaciej> attribute values that would be discarded don't really matter as much as violating content models, in a way
- # [12:02] <othermaciej> because in the latter case, there might not be a conforming document that looks and acts the same (at least, without rewriting in-page scripts)
- # [12:03] <hsivonen> gsnedders: in many cases, you can "fix" content models by wrapping consecutive inline nodes in a single p node
- # [12:19] * Joins: dolphinling (n=chatzill@rbpool3-66.shoreham.net)
- # [12:28] <zcorpan_> perhaps <foo => should be a parse error (since it doesn't do what the spec says in any of ie, safari, opera, firefox)
- # [12:33] <othermaciej> what does the spec say to do?
- # [12:34] <zcorpan_> create an attribute with the name =
- # [12:34] <zcorpan_> | <foo>
- # [12:34] <zcorpan_> | ==""
- # [12:35] <zcorpan_> opera, moz, safari drop the attribute. ie creates an attribute with the empty string as the name
- # [12:35] <othermaciej> the spec behavior is extremely weird then
- # [12:36] * Joins: Ducki (i=Alex@dialin-145-254-189-026.pools.arcor-ip.net)
- # [12:36] <zcorpan_> not really weird. but doesn't match any browser and it's not a parse error
- # [12:37] * Joins: Charl (n=charlvn@196.209.243.8)
- # [12:46] <hsivonen> zcorpan_: email time :-)
- # [12:46] <zcorpan_> emailed
- # [12:54] <othermaciej> zcorpan_: what blows the JS stack on that page is the runner/process mutual recursion
- # [12:55] <othermaciej> zcorpan_: not sure offhand why they call each other but perhaps it could be a loop instead
- # [12:56] <othermaciej> zcorpan_: at some point we will fix the stack limit, it should probably be higher than it is
- # [12:56] <zcorpan_> othermaciej: ah. so it's not the dom2string that is the problem
- # [12:57] <othermaciej> zcorpan_: well, it might have been a problem before, but those recurse deeply enough by themselves to exceed the limit
- # [13:06] <zcorpan_> othermaciej: works when i rewrote it to be a loop
- # [13:07] <othermaciej> zcorpan_: cool
- # [13:07] <othermaciej> zcorpan_: thanks for the workaround
- # [13:27] * maikmerten is now known as maik|bath
- # [14:06] * maik|bath is now known as maikmerten
- # [14:07] <zcorpan_> commited workaround to http://html5.googlecode.com/svn/trunk/parser-tests/
- # [14:11] * Quits: MikeSmith (n=MikeSmit@eM60-254-198-58.pool.emobile.ad.jp) (Read error: 110 (Connection timed out))
- # [14:15] * Joins: webben (i=benh@nat/yahoo/x-dac4fd6e09651351)
- # [14:24] <Philip`> The OCaml preprocessor makes my brain hurt
- # [14:25] <hsivonen> trying to think whether the tree building spec ask implementors do useless stuff takes time...
- # [14:26] * Quits: Charl (n=charlvn@196.209.243.8) (Read error: 110 (Connection timed out))
- # [14:26] * Joins: Charl (n=charlvn@196.209.161.22)
- # [14:27] * Joins: MikeSmith (n=MikeSmit@eM60-254-203-212.pool.emobile.ad.jp)
- # [14:27] * Quits: Charl (n=charlvn@196.209.161.22) (Client Quit)
- # [14:28] <Philip`> Oh, nice, the camlp4 documentation has an example that does precisely what I'm trying to do, which means I don't have to understand anything and can just copy-and-paste it in
- # [14:33] * Joins: Ducki_ (n=Alex@dialin-145-254-189-030.pools.arcor-ip.net)
- # [14:33] * Joins: SavageX (n=maikmert@L931f.l.pppool.de)
- # [14:34] * Quits: ROBOd (n=robod@86.34.246.154) ("http://www.robodesign.ro")
- # [14:34] * Joins: Lachy (n=Lachy@203-214-140-60.perm.iinet.net.au)
- # [14:36] * Joins: rubys (n=rubys@cpe-075-182-064-252.nc.res.rr.com)
- # [14:52] * Quits: maikmerten (n=maikmert@T72ea.t.pppool.de) (Read error: 110 (Connection timed out))
- # [14:53] <zcorpan_> hmm. getElementsByClassName doesn't take a string as argument. it did before, didn't it?
- # [14:54] * SavageX is now known as maikmerten
- # [14:55] * Quits: Ducki_ (n=Alex@dialin-145-254-189-030.pools.arcor-ip.net) (Client Quit)
- # [14:55] * Joins: Ducki_ (n=Alex@dialin-145-254-189-030.pools.arcor-ip.net)
- # [14:55] * Quits: Ducki (i=Alex@dialin-145-254-189-026.pools.arcor-ip.net) (Read error: 110 (Connection timed out))
- # [14:57] * Joins: Codler (n=Codler@84-218-7-136.eurobelladsl.telenor.se)
- # [15:03] <Lachy> zcorpan_: gEBCN() has gone though various iterations including a space separated string, varargs and array of strings.
- # [15:04] <zcorpan_> yeah. i thought it was either string or array. appears it is array only
- # [15:10] <zcorpan_> firefox has implemented it as either string or array
- # [15:10] <zcorpan_> it seems
- # [15:11] <Lachy> which version of FF supports it?
- # [15:12] <zcorpan_> 3
- # [15:12] <zcorpan_> or actually, it only supports array when it has 1 item
- # [15:13] <Lachy> hopefully that can be fixed before FF3 ships
- # [15:13] <zcorpan_> it uses space-separated string
- # [15:13] <zcorpan_> that seems to be more practical anyway to me
- # [15:14] <Lachy> yeah, in some ways it is, but even with an array, it's not hard to do gEBCN(["foo"]);
- # [15:16] <Lachy> the array helps when you're programmatically creating a collection of class names, but the space separated string would probably be better optimised for the majority of cases
- # [15:17] <zcorpan_> classList is an array right
- # [15:17] <zcorpan_> or can be passed to gEBCN
- # [15:17] <Lachy> it probably is
- # [15:18] <Lachy> it's a DOMTokenList
- # [15:18] <Lachy> http://www.whatwg.org/specs/web-apps/current-work/#domtokenlist0
- # [15:19] <zcorpan_> does that fit the definition of "array" wrt what gEBCN can take as argument?
- # [15:19] <Lachy> whether or not a DOMTokenList can be passed to gEBCN would depend on the language binding
- # [15:19] <zcorpan_> for ECMAScript
- # [15:21] <Lachy> ideally, it should be possible to pass a DOMTokenList in all languages. I suggest you send mail about the issue
- # [15:21] <othermaciej> it can be passed, just not clear if the result will be useful
- # [15:21] <othermaciej> unless the toString conversion is defined
- # [15:21] <othermaciej> to do something good
- # [15:21] <othermaciej> which probably it should be
- # [15:22] <Lachy> the toString should probably return a space separated list of tokens as a string.
- # [15:23] <Lachy> but I don't think toString is relevant, given the current definition of gEBCN accepting an array
- # [15:23] <zcorpan_> othermaciej: why does toString matter?
- # [15:23] <othermaciej> I thought it took a string, sorry
- # [15:23] <othermaciej> defining it to take an array is weird
- # [15:23] <zcorpan_> why
- # [15:23] <othermaciej> it should at the very least accept a string also
- # [15:24] <othermaciej> it is true that you can do the varargs thing with an array and it also lets you build up a pre-made array
- # [15:24] <othermaciej> but it makes the common case more awkward
- # [15:24] <othermaciej> and it requires creating a wasteful temporary object for the common case
- # [15:24] <Lachy> yeah
- # [15:25] <othermaciej> and you can use .apply() to pass an array of arguments to a varargs function in JS
- # [15:26] <zcorpan_> perhaps the spec should be changed to only take a space separated string as argument. and defined DOMTokenList.toString to be useful
- # [15:27] <Lachy> it could probably be defined to accept either a space separated string, varargs, array or a DOMTokenList.
- # [15:28] * Joins: webben_ (i=benh@nat/yahoo/x-7bc25586e064ee11)
- # [15:28] <Lachy> I think that would be possible to define, using the IDL described in the latest DOM Language Bindings draft
- # [15:29] * Quits: webben (i=benh@nat/yahoo/x-dac4fd6e09651351) (Read error: 104 (Connection reset by peer))
- # [16:13] * Quits: gsnedders (n=gsnedder@host81-132-88-104.range81-132.btcentralplus.com) ("Don't touch /dev/null…")
- # [16:15] * Joins: annevk (n=annevk@c5144430c.cable.wanadoo.nl)
- # [16:18] * Joins: billmason (n=billmaso@ip156.unival.com)
- # [16:28] * Joins: ROBOd (n=robod@86.34.246.154)
- # [16:33] * Joins: Ducki__ (n=Alex@dialin-145-254-186-042.pools.arcor-ip.net)
- # [16:43] * Quits: annevk (n=annevk@c5144430c.cable.wanadoo.nl) (Read error: 110 (Connection timed out))
- # [16:54] * Quits: othermaciej (n=mjs@17.255.106.198)
- # [16:54] * Quits: webben_ (i=benh@nat/yahoo/x-7bc25586e064ee11) (Read error: 104 (Connection reset by peer))
- # [16:55] * Joins: webben (i=benh@nat/yahoo/x-8d0147ac9e84e25a)
- # [16:55] * Quits: Ducki_ (n=Alex@dialin-145-254-189-030.pools.arcor-ip.net) (Read error: 110 (Connection timed out))
- # [16:57] <Philip`> Ooh, looks like each tokeniser state can only ever be entered with one (or zero) type of current token
- # [16:57] * Quits: ROBOd (n=robod@86.34.246.154) ("http://www.robodesign.ro")
- # [16:58] <Philip`> which is nice because it means I can just cast the current-token pointer without any safety checks, since it's guaranteed to be the right type
- # [17:05] * Quits: webben (i=benh@nat/yahoo/x-8d0147ac9e84e25a) (Read error: 104 (Connection reset by peer))
- # [17:05] * Joins: webben (i=benh@nat/yahoo/x-131b6d0c1936ec66)
- # [17:11] * Quits: rubys (n=rubys@cpe-075-182-064-252.nc.res.rr.com) (Read error: 104 (Connection reset by peer))
- # [17:18] * Joins: hendry (n=hendry@kitten-x.com)
- # [17:59] * Quits: webben (i=benh@nat/yahoo/x-131b6d0c1936ec66) (Read error: 104 (Connection reset by peer))
- # [18:00] * Joins: webben (i=benh@nat/yahoo/x-5e04bed44d7e1be9)
- # [18:05] * Joins: weinig (i=weinig@nat/apple/x-9255b7029f1782e5)
- # [18:11] * Joins: ROBOd (n=robod@86.34.246.154)
- # [18:12] * Joins: gsnedders (n=gsnedder@host81-132-88-104.range81-132.btcentralplus.com)
- # [18:20] * Joins: wildcfo (n=wild_c_f@ool-44c1bb48.dyn.optonline.net)
- # [18:26] * Quits: Ducki__ (n=Alex@dialin-145-254-186-042.pools.arcor-ip.net) (Read error: 104 (Connection reset by peer))
- # [18:35] * Joins: h3h (n=w3rd@66-162-32-234.static.twtelecom.net)
- # [18:36] * Quits: KevinMarks (n=KevinMar@c-76-102-254-252.hsd1.ca.comcast.net) ("The computer fell asleep")
- # [18:48] * Quits: psa (n=yomode@posom.com) (Remote closed the connection)
- # [19:09] * Quits: billmason (n=billmaso@ip156.unival.com) (Read error: 104 (Connection reset by peer))
- # [19:10] * Joins: billmason (n=billmaso@ip156.unival.com)
- # [19:15] * Joins: aroben (n=adamrobe@17.203.15.248)
- # [19:18] * Quits: Lachy (n=Lachy@203-214-140-60.perm.iinet.net.au) ("ChatZilla 0.9.78.1 [Firefox 2.0.0.4/2007051502]")
- # [19:20] * Joins: briansuda (n=briansud@82.221.34.106)
- # [19:24] * Joins: kingryan (n=kingryan@corp.technorati.com)
- # [19:27] * Quits: wildcfo (n=wild_c_f@ool-44c1bb48.dyn.optonline.net) ("This computer has gone to sleep")
- # [19:35] * Quits: BenWard (i=BenWard@nat/yahoo/x-0679d5280a2ae34b) ("Fades out again…")
- # [19:38] * Quits: duryodhan (n=chatzill@221.128.139.94) (Connection timed out)
- # [19:47] * maikmerten is now known as maik|eat
- # [19:48] * Joins: weinig_ (i=weinig@nat/apple/x-4ff3d2259022d6a6)
- # [19:48] * Quits: webben (i=benh@nat/yahoo/x-5e04bed44d7e1be9) (Connection timed out)
- # [19:50] * Quits: weinig (i=weinig@nat/apple/x-9255b7029f1782e5) (Read error: 104 (Connection reset by peer))
- # [19:53] * Joins: KevinMarks (i=KevinMar@nat/google/x-901a3abfa1b6436e)
- # [19:53] * Joins: wildcfo (n=wild_c_f@ool-44c1bb48.dyn.optonline.net)
- # [19:53] * Quits: tndH (i=Rob@83.100.252.160) ("updating cz")
- # [19:56] * Joins: tndH (i=Rob@83.100.252.160)
- # [20:01] * maik|eat is now known as maikmerten
- # [20:02] * Joins: psa (n=yomode@posom.com)
- # [20:13] * Quits: MikeSmith (n=MikeSmit@eM60-254-203-212.pool.emobile.ad.jp) (Read error: 110 (Connection timed out))
- # [20:16] * Joins: MikeSmith (n=MikeSmit@eM60-254-212-198.pool.emobile.ad.jp)
- # [20:23] * Quits: weinig_ (i=weinig@nat/apple/x-4ff3d2259022d6a6)
- # [20:27] * Joins: dbaron (n=dbaron@corp-242.mountainview.mozilla.com)
- # [20:40] * Joins: hasather (n=hasather@22.80-203-71.nextgentel.com)
- # [20:54] * Joins: aroben_ (n=adamrobe@17.255.105.112)
- # [21:08] <gsnedders> FWIW: http://geoffers.no-ip.com/svn/php-html-5-direct — (Barely started) direct implementation of HTML 5's algorithms
- # [21:10] * Quits: aroben (n=adamrobe@17.203.15.248) (Read error: 110 (Connection timed out))
- # [21:11] * Philip` wonders why the list of whitespace characters differs from the list used in the tokeniser
- # [21:14] <gsnedders> Philip`: where is it different? It's the same, just in a different order.
- # [21:14] * Quits: Codler (n=Codler@84-218-7-136.eurobelladsl.telenor.se) ("- nbs-irc 2.21 - www.nbs-irc.net -")
- # [21:14] <Philip`> The tokeniser doesn't do U+000D
- # [21:14] * Quits: wildcfo (n=wild_c_f@ool-44c1bb48.dyn.optonline.net) ("This computer has gone to sleep")
- # [21:14] <gsnedders> "U+000D CARRIAGE RETURN (CR) characters, and U+000A LINE FEED (LF) characters, are treated specially. Any CR characters that are followed by LF characters must be removed, and any CR characters not followed by LF characters must be converted to LF characters. Thus, newlines in HTML DOMs are represented by LF characters, and there are never any CR characters in the input to the tokenisation stage."
- # [21:14] <gsnedders> (Input Stream)
- # [21:15] * Joins: wildcfo (n=wild_c_f@ool-44c1bb48.dyn.optonline.net)
- # [21:15] * Quits: briansuda (n=briansud@82.221.34.106)
- # [21:15] <gsnedders> whereas within an attribute a CR could occur through a entity
- # [21:17] <hsivonen> gsnedders: the entity case maps to LF as well now
- # [21:18] <gsnedders> hsivonen: that was actually changed? ah. I guess the other parts exist to accommodate XHTML5, then?
- # [21:18] * Quits: hendry (n=hendry@kitten-x.com) ("haveagoodWE")
- # [21:18] * Quits: wildcfo (n=wild_c_f@ool-44c1bb48.dyn.optonline.net) (Client Quit)
- # [21:18] <gsnedders> actually, XML changes CR as well
- # [21:19] <gsnedders> "The only way to get a #xD character to match this production is to use a character reference in an entity value literal." — so you can get it through an entity in XML
- # [21:20] <Philip`> Does any of that conversion apply if you do document.write("<b\r>") ?
- # [21:20] <gsnedders> Philip`: it goes through the input stream, so yes
- # [21:22] <Philip`> Ah, okay
- # [21:31] <hsivonen> gsnedders: CR is now in the same table as the Windows-1252 NCRS
- # [21:31] <hsivonen> NCRs
- # [21:31] <hsivonen> gsnedders: if you put an NCR for CR in XML, you get a CR in the infoset/DOM
- # [21:32] <gsnedders> hsivonen: ah. I didn't notice it when I implemented that separately a few days ago (though I did just copy/paste the table and create code automagically). that's what I thought about XML, though.
- # [21:32] <gsnedders> trying to remember what specs say when so tired probably isn't sensible :)
- # [21:33] * hsivonen notes that the fragment case does bad things to control flow
- # [22:02] * Quits: ROBOd (n=robod@86.34.246.154) ("http://www.robodesign.ro")
- # [22:13] * Joins: othermaciej (n=mjs@17.255.106.198)
- # [22:17] * Joins: annevk (n=annevk@c5144430c.cable.wanadoo.nl)
- # [22:27] * Joins: aroben (n=adamrobe@17.203.15.248)
- # [22:28] * Joins: weinig (i=weinig@nat/apple/x-f12217a814ae2e31)
- # [22:29] * Philip` wishes he could find a nice way to output C code from OCaml without just sticking lots of strings together, and without using 25K-line libraries with far too many dependencies
- # [22:33] * Quits: hasather (n=hasather@22.80-203-71.nextgentel.com) (Read error: 110 (Connection timed out))
- # [22:37] * Quits: aroben (n=adamrobe@17.203.15.248)
- # [22:40] * Quits: annevk (n=annevk@c5144430c.cable.wanadoo.nl) (Read error: 110 (Connection timed out))
- # [22:40] * Quits: maikmerten (n=maikmert@L931f.l.pppool.de) ("Leaving")
- # [22:42] * Quits: aroben_ (n=adamrobe@17.255.105.112) (Read error: 110 (Connection timed out))
- # [22:45] * Joins: aroben (n=adamrobe@17.203.15.248)
- # [22:50] * Philip` wonders what would be the easiest way to prove the tokeniser terminates (assuming the character stream is finite)
- # [22:50] <Philip`> (I don't doubt that it does, but I like having a computer agree with me...)
- # [22:51] <hsivonen> oh you are actually proving stuff :-)
- # [22:51] <hsivonen> I just trust the html5lib tests :-)
- # [22:54] <zcorpan_> what is a conforming test case? don't we need conformance requirements for test cases?
- # [22:54] <Dashiva> Can you show the input position is steadily increasing?
- # [22:54] <Philip`> Since I've got the tokeniser in this format, I thought I might as well try proving various forms of correctness, to make sure I don't forget all the logic stuff I learnt at university :-)
- # [22:55] <Philip`> Dashiva: No, since it doesn't always steadily increase - some states don't always consume a character
- # [22:55] <Dashiva> But then you could take those states and how they're always part of a series of states increasing it
- # [22:57] <Philip`> I think that'd probably work - I don't know if it can be done automatically, but I guess it shouldn't be hard to manually define a (partial) ordering of states and check that (input_position, state) is always increasing
- # [22:58] * Quits: othermaciej (n=mjs@17.255.106.198)
- # [22:59] <hsivonen> Philip`: do you use a read()/unread() model?
- # [22:59] <hsivonen> Philip`: can you prove that there are never two consecutive unreads without a read in between?
- # [23:00] <hsivonen> that would at least prove it isn't going backwards
- # [23:01] <Philip`> Is "unread" where the spec says "reconsume the character in the something state"?
- # [23:01] <hsivonen> I've made quite a few optimization by just looking hard at the tree building algorithm without proving anything...
- # [23:01] * Joins: aroben_ (n=adamrobe@17.255.105.112)
- # [23:01] <hsivonen> Philip`: yes
- # [23:01] <hsivonen> Philip`: I call unread() before such transitions
- # [23:02] * Quits: aroben (n=adamrobe@17.203.15.248) (Read error: 104 (Connection reset by peer))
- # [23:03] * Joins: aroben (n=adamrobe@17.203.15.248)
- # [23:03] <Philip`> hsivonen: Okay - I've done about the same, with UnconsumeCharacter/ConsumeCharacter
- # [23:04] <hsivonen> Philip`: btw, what's you character datatype? an UTF-8 code unit? UTF-16 code unit? UTF-32 code unit?
- # [23:05] <Philip`> (I've tried to do as literal a translation of the spec text as possible, but 'unconsume' maps onto the state->state [where 'state' means the whole tokeniser state, not just the explicit ones in the spec] transition model much better than 'reconsume in some other state')
- # [23:06] <Philip`> The C++ implementation just uses a wchar_t, which is 2 or 4 bytes, but it ought to be relatively easy to change that to something better if I had any idea of what would work well
- # [23:09] <Philip`> I'd like to be able to just start with the original correct algorithm, and then have code that optimises it into a less naive structure, and then output that (as C++ or whatever else you want), though currently I've got none of the optimisation bit :-)
- # [23:12] <Philip`> (...and then if the spec changes, it'd all work nicely and easily since the optimisation things would just apply themselves to a different algorithm and produce a new correct tokeniser)
- # [23:12] <Philip`> (I expect this is all far more complex than necessary, but it's fun anyway)
- # [23:19] * Quits: aroben_ (n=adamrobe@17.255.105.112) (Read error: 110 (Connection timed out))
- # [23:23] * Joins: aroben_ (n=adamrobe@17.255.105.112)
- # [23:27] * Joins: csarven (n=nevrasc@modemcable081.152-201-24.mc.videotron.ca)
- # [23:39] * Quits: aroben (n=adamrobe@17.203.15.248) (Read error: 110 (Connection timed out))
- # [23:44] * Quits: weinig (i=weinig@nat/apple/x-f12217a814ae2e31)
- # [23:48] * Joins: othermaciej (n=mjs@17.255.106.198)
- # [23:53] <Hixie> hsivonen: i haven't checked, but re </table>, what about: <table><td><ol><li></table> ?
- # [23:53] <Hixie> vs <table><td><p></table>
- # [23:53] * Quits: wakaba (n=w@118.166.210.220.dy.bbexcite.jp) (Read error: 104 (Connection reset by peer))
- # [23:53] <Hixie> and ignoring the missing <tr>s, oops
- # [23:54] * Joins: wakaba (n=w@118.166.210.220.dy.bbexcite.jp)
- # [23:55] * Quits: kingryan (n=kingryan@corp.technorati.com)
- # [23:55] * Quits: wakaba (n=w@118.166.210.220.dy.bbexcite.jp) (Read error: 104 (Connection reset by peer))
- # [23:55] <hsivonen> Hixie: well, yeah. I guess we want the errors there after all. my point was that <ol> gets one error anyway when it goes on the stack
- # [23:55] * Joins: wakaba (n=w@118.166.210.220.dy.bbexcite.jp)
- # [23:59] * Joins: webben (n=benh@91.84.193.157)
- # Session Close: Sat Jul 07 00:00:00 2007
The end :)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}