Options:
- # Session Start: Sat Jul 07 00:00:00 2007
- # Session Ident: #whatwg
- # [00:01] * Joins: weinig (i=weinig@nat/apple/x-0a38def2ae42cc65)
- # [00:01] * Joins: webben_ (n=benh@dip5-fw.corp.ukl.yahoo.com)
- # [00:10] * Joins: aroben (n=adamrobe@17.203.15.248)
- # [00:12] <Hixie> hsivonen: not in that case, you're in a cell there
- # [00:18] * Quits: webben (n=benh@91.84.193.157) (Read error: 110 (Connection timed out))
- # [00:19] * Joins: hober (n=ted@unaffiliated/hober)
- # [00:24] <hsivonen> Hixie: ooh. good point.
- # [00:24] <hsivonen> Hixie: except then you aren't IN_TABLE
- # [00:26] <hsivonen> well, I implemented the spec now
- # [00:26] * Quits: aroben_ (n=adamrobe@17.255.105.112) (Read error: 110 (Connection timed out))
- # [00:28] <Hixie> doesn't in-cell defer to in-table in that case?
- # [00:29] <hsivonen> no. it closes the cell first
- # [00:32] <Hixie> ah
- # [00:32] <Hixie> hm
- # [00:32] <Hixie> well i'll look at it in detail at some point
- # [00:32] <Hixie> :-)
- # [00:49] * Joins: weinig_ (n=weinig@17.255.104.223)
- # [00:58] * Quits: weinig (i=weinig@nat/apple/x-0a38def2ae42cc65) (Read error: 110 (Connection timed out))
- # [00:58] * Quits: zcorpan_ (n=zcorpan@84-216-41-227.sprayadsl.telenor.se) (Read error: 110 (Connection timed out))
- # [01:17] <Hixie> gotta love some e-mails
- # [01:17] <Hixie> "i wonder why there's still no a special 'key' attribute for every form field implemented."
- # [01:21] * weinig_ is now known as weinig
- # [01:21] * Quits: billmason (n=billmaso@ip156.unival.com) (".")
- # [01:36] * Joins: Severian (n=Severian@24-155-40-202.ip.grandenetworks.net)
- # [01:37] * Quits: tndH (i=Rob@83.100.252.160) ("ChatZilla 0.9.78.1-rdmsoft [XULRunner 1.8.0.9/2006120508]")
- # [01:57] * Joins: billyjack (n=MikeSmit@eM60-254-216-27.pool.emobile.ad.jp)
- # [02:09] * Quits: aroben (n=adamrobe@17.203.15.248)
- # [02:12] * Quits: webben_ (n=benh@dip5-fw.corp.ukl.yahoo.com)
- # [02:14] * Quits: MikeSmith (n=MikeSmit@eM60-254-212-198.pool.emobile.ad.jp) (Read error: 110 (Connection timed out))
- # [02:20] * Joins: zcorpan_ (n=zcorpan@84-216-41-3.sprayadsl.telenor.se)
- # [02:24] * Quits: KevinMarks (i=KevinMar@nat/google/x-901a3abfa1b6436e) ("The computer fell asleep")
- # [02:25] <zcorpan_> why is there discussion about selectors api on the whatwg list?
- # [02:27] <othermaciej> sidetrack
- # [02:37] * Joins: webben (n=benh@82.152.177.224)
- # [02:44] * Quits: bzed (n=bzed@dslb-084-059-113-101.pools.arcor-ip.net) ("Leaving")
- # [02:46] * billyjack is now known as MikeSmith
- # [02:50] * Quits: csarven (n=nevrasc@modemcable081.152-201-24.mc.videotron.ca) (Read error: 110 (Connection timed out))
- # [02:58] * Joins: weinig_ (i=weinig@nat/apple/x-a63858e4aa1ea0e2)
- # [03:03] <Philip`> If html5lib throws an exception when parsing, does that count as a bug?
- # [03:05] * Quits: zcorpan_ (n=zcorpan@84-216-41-3.sprayadsl.telenor.se) (Read error: 110 (Connection timed out))
- # [03:07] * Quits: Severian (n=Severian@24-155-40-202.ip.grandenetworks.net) ("Leaving")
- # [03:12] * Quits: weinig_ (i=weinig@nat/apple/x-a63858e4aa1ea0e2) (Read error: 104 (Connection reset by peer))
- # [03:12] * Joins: weinig_ (i=weinig@nat/apple/x-5dc692ef14c00e32)
- # [03:12] * Quits: h3h (n=w3rd@66-162-32-234.static.twtelecom.net) ("|")
- # [03:14] * Quits: weinig (n=weinig@17.255.104.223) (Read error: 110 (Connection timed out))
- # [03:14] * weinig_ is now known as weinig
- # [03:19] * Quits: psa (n=yomode@posom.com) ("All things must come to an end")
- # [03:25] * Joins: psa (n=yomode@posom.com)
- # [03:47] * Quits: othermaciej (n=mjs@17.255.106.198)
- # [03:51] <Philip`> Hmm, I get quite different results in html5lib vs my tokeniser when there's a \r
- # [03:51] <Philip`> (Maybe it's doing some kind of translation to \r at some point?)
- # [04:01] <Hixie> what results do you get?
- # [04:02] <Hixie> (you should get a character token U+0010)
- # [04:08] <Philip`> With input like "<x\r>", html5lib gives a start tag called "x", whereas I get one called "x\r"
- # [04:10] * Quits: weinig (i=weinig@nat/apple/x-5dc692ef14c00e32)
- # [04:10] <Philip`> I suppose that doesn't matter since the input stream preprocessing bit says "there are never any CR characters in the input to the tokenisation stage"
- # [04:11] <Philip`> (but I don't have any input stream preprocessing - I'm just pushing characters straight into the tokeniser)
- # [04:22] <Hixie> ah
- # [04:22] <Hixie> you'll want some input stream preprocessing
- # [04:22] <Hixie> it's part of the parser spec
- # [04:22] <Hixie> ensures there are no NULLs, CRs, etc
- # [04:23] <Hixie> it's important because <p\r\ntitle="..."> ...is common in HTML, and you want to not treat that as something other than a <p> tag!
- # [04:23] <Hixie> bbiab
- # [04:49] * Joins: othermaciej (n=mjs@dsl081-048-145.sfo1.dsl.speakeasy.net)
- # [04:59] * Quits: dbaron (n=dbaron@corp-242.mountainview.mozilla.com) ("8403864 bytes have been tenured, next gc will be global.")
- # [05:10] * Joins: weinig (n=weinig@c-67-188-89-242.hsd1.ca.comcast.net)
- # [05:21] * Quits: othermaciej (n=mjs@dsl081-048-145.sfo1.dsl.speakeasy.net)
- # [05:22] * Joins: othermaciej (n=mjs@dsl081-048-145.sfo1.dsl.speakeasy.net)
- # [05:25] * Quits: othermaciej (n=mjs@dsl081-048-145.sfo1.dsl.speakeasy.net) (Client Quit)
- # [05:26] * Joins: othermaciej (n=mjs@dsl081-048-145.sfo1.dsl.speakeasy.net)
- # [05:29] * Quits: othermaciej (n=mjs@dsl081-048-145.sfo1.dsl.speakeasy.net) (Client Quit)
- # [05:30] * Joins: othermaciej (n=mjs@dsl081-048-145.sfo1.dsl.speakeasy.net)
- # [05:30] * Quits: mpt (n=mpt@canonical/launchpad/mpt) ("This computer has gone to sleep")
- # [06:29] * Joins: h3h (n=w3rd@cpe-76-88-44-219.san.res.rr.com)
- # [06:34] * Quits: othermaciej (n=mjs@dsl081-048-145.sfo1.dsl.speakeasy.net) (Read error: 110 (Connection timed out))
- # [07:00] * Joins: othermaciej (n=mjs@dsl081-048-145.sfo1.dsl.speakeasy.net)
- # [07:07] * Joins: aroben (n=adamrobe@c-67-160-250-192.hsd1.ca.comcast.net)
- # [07:08] * Quits: aroben (n=adamrobe@c-67-160-250-192.hsd1.ca.comcast.net) (Remote closed the connection)
- # [07:08] * Joins: aroben (n=adamrobe@c-67-160-250-192.hsd1.ca.comcast.net)
- # [07:14] <Hixie> hey did we ever hear back on "Steven: I believe that XHTML2 is more backwards compatible than HTML5, and I plan to make a document comparing them to demonstrate it.
- # [07:14] <Hixie> "?
- # [07:14] <Hixie> If there are real problems I want to fix them
- # [07:16] <othermaciej> I haven't heard anything
- # [07:21] <Hixie> going through this discussion, i actually came across another argument (from Mark Birbeck) for why we _shouldn't_ call it XHTML1.5
- # [07:21] <Hixie> XHTML 1.5 implies it was evolved from XHTML 1.1
- # [07:21] <Hixie> which it isn't (at all), it's evolved from HTML5
- # [07:22] <Hixie> not that it's a big deal, just thought of it
- # [07:30] * Joins: mpt (n=mpt@121-72-128-43.dsl.telstraclear.net)
- # [07:50] * Quits: mpt (n=mpt@121-72-128-43.dsl.telstraclear.net) (Connection timed out)
- # [08:17] * Quits: MikeSmith (n=MikeSmit@eM60-254-216-27.pool.emobile.ad.jp) (Read error: 110 (Connection timed out))
- # [08:17] * Joins: billyjack (n=MikeSmit@eM60-254-197-40.pool.emobile.ad.jp)
- # [09:08] * Quits: aroben (n=adamrobe@c-67-160-250-192.hsd1.ca.comcast.net)
- # [09:09] * Joins: KevinMarks (n=KevinMar@c-76-102-254-252.hsd1.ca.comcast.net)
- # [09:25] * Joins: Ducki (n=Alex@dialin-145-254-189-111.pools.arcor-ip.net)
- # [09:28] <billyjack> HTMLX
- # [09:28] * billyjack is now known as MikeSmith
- # [09:29] <MikeSmith> HTML5X
- # [09:32] * Quits: MikeSmith (n=MikeSmit@eM60-254-197-40.pool.emobile.ad.jp) ("Less talk, more pimp walk.")
- # [09:54] * Joins: mikeday (n=mikeday@CPE-60-224-50-129.vic.bigpond.net.au)
- # [09:54] * Joins: MikeSmith (n=MikeSmit@eM60-254-200-76.pool.emobile.ad.jp)
- # [09:56] * Parts: MikeSmith (n=MikeSmit@eM60-254-200-76.pool.emobile.ad.jp) ("Less talk, more pimp walk.")
- # [09:57] * Joins: MikeSmith (n=MikeSmit@eM60-254-200-76.pool.emobile.ad.jp)
- # [10:12] <Dashiva> Hixie: I guess it's HTML 1.0.5 then :)
- # [10:20] * Joins: Codler (n=Codler@84-218-7-247.eurobelladsl.telenor.se)
- # [10:28] * Quits: h3h (n=w3rd@cpe-76-88-44-219.san.res.rr.com)
- # [10:32] * Joins: tndH (i=Rob@83.100.252.160)
- # [10:33] <jgraham> Philip`: If html5lib throws an exception it's almost certianly a bug
- # [10:37] * Joins: hasather (n=hasather@22.80-203-71.nextgentel.com)
- # [10:42] * Quits: Codler (n=Codler@84-218-7-247.eurobelladsl.telenor.se) ("- nbs-irc 2.21 - www.nbs-irc.net -")
- # [10:45] * Quits: weinig (n=weinig@c-67-188-89-242.hsd1.ca.comcast.net)
- # [10:51] <webben> Hixie: I don't know if you follow Amaya development, but they've just implemented http://www.ietf.org/internet-drafts/draft-wilde-text-fragment-07.txt ... which may suggest it would be worth a second look wrt video fragment addressing.
- # [10:52] <webben> here's the test the mailing list suggests: http://www.ietf.org/internet-drafts/draft-wilde-text-fragment-07.txt#char=20090,20109
- # [10:54] <Hixie> good to know their focussing on their most critical bugs
- # [10:54] <Hixie> they're, even
- # [10:55] <Hixie> i don't really have a problem with using fragment identifiers to seek into video, per se, i just don't think it really fits the JS API
- # [10:55] <Hixie> i guess we could define the fragment identifier to set the default value of 'start' or whatever that attribute is called
- # [10:55] <Hixie> when i last looked at them it was before we had the (more) complex set of attributes we do now
- # [11:02] * Joins: ROBOd (n=robod@86.34.246.154)
- # [11:03] * Joins: Ducki_ (n=Alex@dialin-145-254-189-028.pools.arcor-ip.net)
- # [11:05] <MikeSmith> Hixie, I know the discussion about naming of the XML serialization is really just a distraction, but I think the idea of trying to avoid ambiguity maybe has some merit .. HTMLX or HTML5X seem possibly appropriate: unambiguous, short and simple, new (and exciting!) and much more in the WHATWG spirit than adopting a legacy name with baggage already attached to it
- # [11:06] <mikeday> HTML is a legacy name with a fair bit of baggage attached to it :)
- # [11:08] <MikeSmith> mikeday - true, but a bit of a different thing, isn't it ...
- # [11:08] <mikeday> at least XHTML5 gives the W3C three more versions of XHTML to play with themselves :)
- # [11:08] <MikeSmith> heh
- # [11:10] <MikeSmith> Anyway, I think that we want the HTML name and that there is no point in using anything but it is clear ... but IMHO we don't really want the XHTML name for the XML serialization and would really gain nothing by using it
- # [11:11] <mikeday> seems reasonable, but most people do think of XHTML as being "HTML serialised as XML"
- # [11:11] <Hixie> MikeSmith: if it's an issue at all, i agree with DanC that the spec that should change name is XHTML2 (since it isn't really "HTML")
- # [11:11] <Hixie> MikeSmith: but i'm not convinced there's an issue, i'm happy for both groups to co-exist
- # [11:12] <Hixie> MikeSmith: "XHTML" is what the XML serialisation of HTML is called, it's been that way for years (since 1999 at least)
- # [11:12] <MikeSmith> Hixie - the fact that something has been a certain way for years is not a convincing argument for keeping it that way :)
- # [11:13] <Hixie> for names, it is
- # [11:13] <MikeSmith> I think you better than anybody else can probably understand that well :)
- # [11:13] <Hixie> how so?
- # [11:15] <webben> Hixie: It's an open source project, so it's not necessarily th
- # [11:15] <webben> the case that it was implemented by the core team.
- # [11:15] <Hixie> webben: true
- # [11:16] <MikeSmith> Hixie - Well, because your work on HTML5 has been in many ways a clear break with the past of XHTML, a reassessment of what the real problems are and a different approach to fixing them
- # [11:17] <mikeday> a clear break... <br clear="all">, presumably.
- # [11:17] <Hixie> Mike: i don't understand how that means we should change names. If anything, the whole point of keeping backwards compatibility suggests we should not change the names willy nilly.
- # [11:19] <MikeSmith> I don't think it'd be willy nilly at all and backwards compatibility with respect to supporting existing content on the Web is something very different than backwards compatibility in naming
- # [11:19] <MikeSmith> we could not break anything by renaming the XML serialization
- # [11:20] <MikeSmith> we would break a whole lot of stuff by not supporting backward compatibility with existing content
- # [11:20] <webben> or little bits of stuff, in the cases where backwards compatibility is already broken
- # [11:20] <webben> Can't this issue get escalated to TBL already?
- # [11:21] <webben> I think XHTML5 is a crazy choice, but this issue does seem to be taking up too much time.
- # [11:21] <mikeday> I like the sound of XHTML II Turbo Championship Edition
- # [11:21] <MikeSmith> It could be decided by Tim but why should it be?
- # [11:21] <webben> MikeSmith: as i understand it, that's W3C process.
- # [11:21] <MikeSmith> if a whole new name is chosen we don't need to ask for anybody's permission
- # [11:22] <webben> MikeSmith: Yes, but that doesn't seem likely at this point.
- # [11:22] <MikeSmith> and if a whole new name is chosen, we don't need to continue unproductive discussions with others about it
- # [11:23] <MikeSmith> webben - nothing is sacred, nothing is written in stone at this point, our options are wide open
- # [11:23] <MikeSmith> with regard to this name
- # [11:23] * Joins: maikmerten (n=maikmert@L931f.l.pppool.de)
- # [11:23] <webben> MikeSmith: I mean if the WHATWG community is not already persuaded this is a bad idea, it's unlikely more arguments will persuade them. The issues involved aren't technical.
- # [11:24] <Hixie> there really is no issue here
- # [11:24] <webben> Hixie: If there was no issue, then it wouldn't be an issue to change the name.
- # [11:24] <webben> It would just be changed.
- # [11:24] <Hixie> the name is "HTML5"
- # [11:24] <webben> obviously there are issues here
- # [11:25] <Hixie> we don't have a spec called "XHTML5"
- # [11:25] * Parts: hasather (n=hasather@22.80-203-71.nextgentel.com)
- # [11:25] <MikeSmith> Hixie - true that. but within the spec the term is used
- # [11:26] <webben> Hixie: Then it would be no issue to disassociate HTML5 from XHTML5.
- # [11:26] <Hixie> the only mention of "XHTML5" in the spec is in relation to a conformance class
- # [11:27] <Hixie> webben: you can't disassociate them. they're associated in the mind of millions of people, with thousands of blog posts and e-mails already referring to the XML HTML5 variant by that name.
- # [11:27] * Quits: Ducki (n=Alex@dialin-145-254-189-111.pools.arcor-ip.net) (Read error: 113 (No route to host))
- # [11:27] <mikeday> millions of people? seriously?
- # [11:27] <Hixie> well, "millions" might be overstating the case
- # [11:27] <webben> Hixie: The WHATWG community appears to think that it would be feasible for XHTML2 to change it's official name. You could come up with an official name for the XML serialization.
- # [11:27] * mikeday grins
- # [11:27] <Hixie> tens of thousands, certainly
- # [11:27] <mikeday> thousands, quite likely
- # [11:27] <mikeday> hundreds, almost definitely
- # [11:28] <hsivonen> we could remove the string "XHTML5" from the spec
- # [11:28] <webben> Lets not pretend it's impossible for either group to change their name.
- # [11:28] <Hixie> webben: i really don't care if xhtml2 changes its name. i don't think it's an issue at all.
- # [11:28] <mikeday> at least one or two people on the planet know the difference between HTML and XHTML and XML :)
- # [11:28] <webben> Hixie: What do you mean by "an issue"?
- # [11:28] <hsivonen> but putting a name for the XML serialization that doesn't begin with "XHTML" makes no sense
- # [11:28] <Hixie> webben: a problem. a topic worth consideration. something that will cause harm and that needs changing.
- # [11:29] <MikeSmith> Hixie - but that doesn't mean it needs to stay that way, and it's not a convincing argument for keeping it that way ... if we use a different name, by a month from now, a few hundred or thousands will have blogged about that
- # [11:29] <webben> Hixie: Ah okay, I mean it's an issue of disagreement.
- # [11:29] <MikeSmith> hsivonen - why?
- # [11:29] <Hixie> MikeSmith: even if we use a different name, people will still refer to "xhtml", and the version of the language is "5" (as in html5), so they'll call it "xhtml5".
- # [11:29] <hsivonen> MikeSmith: because the XML formulation of HTML is known as "XHTML"
- # [11:30] <Hixie> MikeSmith: it's just a natural association
- # [11:30] <webben> I don't see any evidence that the majority would not use a different name for XHTML2 or XHTML5.
- # [11:30] <hsivonen> MikeSmith: the XHTML2 WG is confusing things by calling something that isn't an XML formulation of HTML "XHTML" for their marketing purposes
- # [11:31] <hsivonen> MikeSmith: but by and large, the "XHTML" people out there care about is the XML formulation of HTML 4
- # [11:31] <webben> Which concedes the general principle that this is an issue.
- # [11:31] <webben> the whoever are "confusing things"
- # [11:31] * Quits: mikeday (n=mikeday@CPE-60-224-50-129.vic.bigpond.net.au) ("-")
- # [11:31] <Hixie> webben: the majority of people will never even hear about xhtml2
- # [11:31] <webben> confusion is an issue (something that causes harm)
- # [11:31] <webben> Hixie: Who is "people"?
- # [11:31] <Hixie> web authors
- # [11:32] <Hixie> people who will hear about xhtml
- # [11:32] <Hixie> people who write html documents
- # [11:32] <webben> Hixie: The majority of web authors haven't heard about XHTML.
- # [11:32] <webben> Those who have heard of XHTML are quite likely to have heard about XHTML2.
- # [11:32] <Hixie> i disagree
- # [11:33] <hsivonen> webben: I don't believe that statement
- # [11:33] <webben> Hixie: random blog commenters author HTML.
- # [11:33] <Hixie> "-//W3C//DTD XHTML 1.0 Transitional//EN" is the most common DOCTYPE
- # [11:33] <MikeSmith> hsivonen - in the past the XML formulation of HTML has been called XHTML, but there is no fundamental reason why it needs to remain that way
- # [11:33] <webben> Hixie: yes, usually created by a CMS.
- # [11:33] <MikeSmith> and "XHTML" now means more than just "XML formulation of HTML"
- # [11:33] <webben> indeed
- # [11:33] <MikeSmith> implies more
- # [11:33] <webben> it means tag soup
- # [11:33] <Hixie> webben: well, in any case, if they haven't heard about xhtml at all, then there's no problem at all.
- # [11:34] <hsivonen> webben: more to the point, of the people who *think* they are using XHTML, virtually 100% purports to use XHTML 1.0 or 1.1
- # [11:34] <Hixie> webben: since they can hardly get confused about version numbers without hearinga bout it in the first place
- # [11:34] <webben> hsivonen: Well of course. They shouldn't be using XHTML2 yet.
- # [11:34] <MikeSmith> XHTML means HTML is valid against a certain doctype
- # [11:34] <webben> hsivonen: and if you mean purports, all that reflects is CMS choices.
- # [11:34] <hsivonen> MikeSmith: what does it mean? any spec published by the XHTML2 WG regardless of the nature of the language specified?
- # [11:34] <MikeSmith> or aims to be
- # [11:34] <webben> e.g. WordPress
- # [11:34] <webben> *if you mean by purports the doctype
- # [11:35] <MikeSmith> hsivonen - I think we need to quit caring what it means and choose a different name
- # [11:35] <hsivonen> webben: by purports, I mean the Appendix C delusion
- # [11:35] <Hixie> MikeSmith: i don't understand why you think there's a problem with the name.
- # [11:35] <MikeSmith> XHTML is a net liability to us as a name
- # [11:35] <webben> hsivonen: Yes precisely. it hardly argues XHTML is a good name for an XML serialization.
- # [11:35] <MikeSmith> Hixie - because of its legacy and its connotations
- # [11:36] <hsivonen> webben: I think that argument is more persuasive than any argument involving a claim by the XHTML2 WG
- # [11:36] <Hixie> well that's a new argument, i have to say
- # [11:36] <Hixie> haven't heard that one before
- # [11:36] <MikeSmith> and the fact that using it is creating contentious, distracting, unproductive debate
- # [11:36] <webben> I'm pretty sure I've made it before in this channel.
- # [11:36] <hsivonen> "XHTML" is much more tainted by the infamous Appendix C than associated with XHTML2
- # [11:37] <Hixie> MikeSmith: i don't think changing the name will affect that, though, i think the solution to that is to do what the html5 spec does, and basically relegate xhtml to a bastard stepchild status.
- # [11:37] <Hixie> MikeSmith: there's a reason the spec is just called "html5" and not "html5 and xhtml5" or "(x)html5" or anything
- # [11:37] <MikeSmith> the are much more important battles to fight, creating one by staying wedded to that name is fight that isn't worth fighting
- # [11:38] <MikeSmith> Hixie - I now there's a reason, and I understand it to be a very good reason
- # [11:38] <webben> I'd prefer that we didn't think of it in terms of battles.
- # [11:38] <Hixie> i'm totally with you that we shouldn't fight this battle
- # [11:38] <MikeSmith> hsivonen - "tainted" is a apt word
- # [11:38] <Hixie> in fact, i've every intention of just walking away from it
- # [11:38] <Hixie> and ignoring it
- # [11:39] <MikeSmith> Hixie - fine for you to make that choice ... unfortunately, that's really not an option for the rest of us
- # [11:39] <MikeSmith> ignoring a problem does not make it go away, sadly
- # [11:39] <Hixie> why not?
- # [11:39] <Hixie> there's no problem
- # [11:39] <Hixie> that's my point
- # [11:39] <hsivonen> Hixie: the problem is that common concepts need short names
- # [11:40] <Hixie> so xhtml has a bad rep. big deal. xhtml is dead, long live html.
- # [11:40] <webben> Hixie: I think that to persuade people there is no problem, you'd have to not ignore the "problem" that people think there is a problem.
- # [11:40] <hsivonen> (except in the SGML circles where the most common concepts have the longest names)
- # [11:40] <Hixie> webben: heh
- # [11:40] <MikeSmith> hsivonen - heh. lol about that SGML naming comment
- # [11:41] <webben> XHTML doesn't have a bad rep except among a tiny minority of web authors.
- # [11:42] <Hixie> xhtml having a bad rep is the only reason MikeSmith gave for changing its name
- # [11:42] <webben> Most XHTML users are quite happy to serve Appendix C style faux-XHTML.
- # [11:42] <Hixie> so if xhtml doesn't have a bad rep, then great, we don't have to change the name
- # [11:42] <MikeSmith> Hixie - No, I didn't say the bad rep was the only reason
- # [11:42] <webben> It's not that it has a bad rep, it's that it means something different.
- # [11:42] <webben> (which is why it has a bad rep among that tiny minority)
- # [11:43] <Hixie> MikeSmith: i didn't say you said it was the only reason. i said it was the only reason you gave.
- # [11:43] <Hixie> webben: means something different than what?
- # [11:43] <MikeSmith> I said it's ambiguous and it implies things more than just an XML serialization of HTML
- # [11:43] <hsivonen> webben: we want those authors to migrate to HTML5 as text/html, not XHTML5 with wrong Content-Type
- # [11:43] <MikeSmith> it implies validity instead of just well-formedness
- # [11:43] <Hixie> hsivonen: don't worry, they can't migrate to xhtml5 with wrong mime type. xhtml5 is defined in terms of mime types. :-D
- # [11:43] <MikeSmith> among other things
- # [11:43] <Hixie> uh
- # [11:43] <Hixie> what?
- # [11:44] <Hixie> html4, xhtml1, html5, and xhtml5 have exactly the same concepts of conformance
- # [11:44] <MikeSmith> A set of authoring practices
- # [11:44] <webben> hsivonen: Well sure. That's another good reason not to have XHTML5 as a name.
- # [11:44] <webben> hsivonen: It makes the intention much clearer.
- # [11:44] <MikeSmith> xhtml1 is a language with a schema
- # [11:44] <webben> XHTML1 as She is Wrote isn't.
- # [11:45] <MikeSmith> xhtml in fact has rules that are a superset of XML conformance and well-formedness rules
- # [11:45] <MikeSmith> such as, requiring that document instances must contain a doctype
- # [11:45] <Hixie> MikeSmith: xhtml1 and html4 both have a set of conformance rules that you must obey in order to be conforming.
- # [11:46] <webben> MikeSmith: XHTML doesn't require that; XHTML 1.0 and 1.1 do.
- # [11:46] <webben> AFAIK.
- # [11:46] <Hixie> MikeSmith: just like the html5 and xhtml5 languages
- # [11:46] <MikeSmith> Hixie - yeah, and they are two different sets of rules
- # [11:46] <Hixie> MikeSmith: such as having a doctype in the case of xhtml1.x, and such as putting valid URIs in href="" attributes
- # [11:46] <Hixie> MikeSmith: they have four different sets of rules
- # [11:47] <Hixie> MikeSmith: heck even xhtml1.0 and 1.1 have different rules.
- # [11:47] <webben> MikeSmith: see e.g. http://www.w3.org/TR/xhtml1/#well-formed
- # [11:47] <Hixie> wouldn't be much point having different versions if they were identical!
- # [11:47] <hsivonen> Hixie: you are presupposing that there is a point!
- # [11:48] <Hixie> hsivonen: granted!
- # [11:48] <webben> hsivonen: Ruby. That /is/ a point.
- # [11:48] <webben> http://www.w3.org/TR/xhtml11/changes.html#a_changes
- # [11:48] <webben> Talking of which, has WHATWG specced Ruby in HTML yet?
- # [11:48] <Hixie> webben: no, it's on my pile of things to do
- # [11:48] <webben> cool :)
- # [11:49] <hsivonen> webben: the joke is that Ruby only sort of works in IE which wants it as text/html
- # [11:49] <webben> hsivonen: I was going to say, should be easy to include given IE's support in text/html.
- # [11:49] <webben> Amaya supports Ruby too.
- # [11:50] <Hixie> "easy" isn't the word i would use
- # [11:50] <krijnh> Too? Does Amaya support anything else? :)
- # [11:50] <Hixie> anne did some research on the error handling rules we'll have to add
- # [11:50] <webben> There's also: https://addons.mozilla.org/en-US/firefox/addon/1935
- # [11:50] <hsivonen> webben: I forget the standard quatifier: in set {Trident, Presto, Gecko, WebKit}
- # [11:50] <Hixie> but i haven't checked if they're enough
- # [11:50] <webben> hsivonen: Mozilla developers seem to believe that having extensions support things counts as support.
- # [11:51] <hsivonen> webben: Mozilla developers or random Bugzilla commentators?
- # [11:51] <webben> hsivonen: If the core devs don't disagree, doesn't seem much difference.
- # [11:51] <MikeSmith> The fact that the XML serialization of HTML has a quite different sets of rules from the XHTML 1.x/2 language would seem to me to suggest that it would be good to have a clearly different name for it, that unambiguously disassociates it from the extra rules of XHTML
- # [11:51] <webben> it's a status quo
- # [11:52] <MikeSmith> webben - true on that comment about extensions being counted as support
- # [11:52] <Hixie> MikeSmith: the XML serialisation of HTML5 has very similar rules to XHTML1.0
- # [11:52] <Hixie> MikeSmith: and both of those have very different rules to XHTML2
- # [11:53] <webben> but different semantics
- # [11:53] <webben> (as with HTML)
- # [11:53] <hsivonen> webben: I hadn't noticed that regarding layout feature support. true for UI features, though
- # [11:53] <MikeSmith> having third-party extensions to your application, ones that you can blow off any responsibility at all for, is not a way to ensure that users have the best user experience of your application
- # [11:53] <webben> My point is less about what is good or bad practice, as that assessment of "what is supported" must include extensions.
- # [11:55] <webben> There are major advantages to having extensions, because they provide a testing ground for UIs for things like microformats.
- # [11:57] <webben> Even if they do also create an incentive not to add features to core.
- # [11:57] <MikeSmith> Of course there are big advantages, but having a powerful plug-in architecture does not mean that you should require users to install extensions in order to have access to key features
- # [11:57] <webben> MikeSmith: agreed
- # [11:58] <hsivonen> for practical purposes, *Gecko* doesn't support Ruby even if there's a fringe way to hack support into Firefox
- # [11:59] <MikeSmith> hsivonen - is that true of the mozilla2 codebase also?
- # [12:00] <Hixie> what mozilla2 codebase?
- # [12:00] <hsivonen> MikeSmith: dunno. I'm thinking the Firefox 2/3 timeframe
- # [12:01] <hsivonen> (I don't even know if the Mozilla2 major refactorings have gone forward yet)
- # [12:01] <MikeSmith> Hixie - I guess I assumed there is already exising mozilla2 code, from reading Brendan's roadmap stuff
- # [12:11] <webben> hsivonen: Why is what a particular rendering engine supports significant?
- # [12:11] <webben> surely what's important is: what can end-users readily do with some markup
- # [12:11] <webben> if it's implemented in Amaya only, they can't really do much, because switching to Amaya is weird
- # [12:11] <Hixie> MikeSmith: as far as i know there's only one codebase
- # [12:11] <webben> but installing a Fx extension is a piece of cake
- # [12:12] <webben> the rendering engine is only one component of the end-user experience that the Mozilla ecoystem offers
- # [12:13] <webben> sorry not, why is it significant, why is it the only significant thing i should say
- # [12:13] <webben> obviously core Gecko support would be preferable.
- # [12:14] <MikeSmith> Hixie - OK. I thought Brendan had said they'd try to be shipping Firefox 4 some time in 2008 based on the new/refactored moz2 codebase (including integrating Tamarin in) ... seems it would be difficult for them to ship 2008 if the work hasn't actually started yet
- # [12:14] <Hixie> MikeSmith: indeed.
- # [12:15] <webben> interesting, according to https://bugzilla.mozilla.org/show_bug.cgi?id=33339, IE's Ruby-in-HTML implementation does conform roughly to a working draft of Ruby that allowed that.
- # [12:15] * Joins: Codler (n=Codler@84-218-7-247.eurobelladsl.telenor.se)
- # [12:17] * MikeSmith wonders what the timeframe is for browsers based on the QT port of Webkit might be
- # [12:18] * Quits: Codler (n=Codler@84-218-7-247.eurobelladsl.telenor.se) (Client Quit)
- # [12:19] <MikeSmith> I think (hope) having a Qt-based WebKit is going to be a huge boost for getting better browsers onto more mobile devices
- # [12:19] <webben> is it?
- # [12:20] <webben> what do current devices that might use a QT-based webkit use now?
- # [12:21] * Joins: Ducki__ (i=Ducki@213-102-101-211.cust.tele2.de)
- # [12:22] * Joins: zcorpan_ (n=zcorpan@84-216-42-70.sprayadsl.telenor.se)
- # [12:23] <MikeSmith> webben - well, they do have one very good option already, which is Opera Mobile
- # [12:23] <MikeSmith> for the Qtopia platform
- # [12:23] <webben> What would webkit add to that?
- # [12:23] * Joins: Ducki (n=Alex@dialin-212-144-064-168.pools.arcor-ip.net)
- # [12:24] <webben> (not saying it would be a bad thing, just wondering what the big deal would be)
- # [12:24] <MikeSmith> webben - choice?
- # [12:24] <webben> ah okay
- # [12:25] * Quits: Ducki (n=Alex@dialin-212-144-064-168.pools.arcor-ip.net) (Read error: 104 (Connection reset by peer))
- # [12:26] <MikeSmith> and more competition, and thus more incentive to add more features and improve performance ...
- # [12:26] * Joins: Ducki (i=Alex@nrdh-d9b98030.pool.mediaWays.net)
- # [12:27] <MikeSmith> and make users and device manufacturers and mobile operators realize we don't need to keep shipping handsets with the sucky browsers that many of them now have
- # [12:27] * MikeSmith is running out of battery and will have to drop off soon
- # [12:29] <MikeSmith> hey this is cool (to me at least) -
- # [12:29] <MikeSmith> [[
- # [12:29] <MikeSmith> <CIA-5> ap * r24088 /trunk/ (12 files in 6 dirs): (log message trimmed)
- # [12:29] <MikeSmith> <CIA-5> Reviewed by Maciej.
- # [12:29] <MikeSmith> <CIA-5> http://bugs.webkit.org/show_bug.cgi?id=14525
- # [12:29] <MikeSmith> <CIA-5> Support exslt:node-set()
- # [12:29] <MikeSmith> <CIA-5> Test: fast/xsl/exslt-node-set.xml
- # [12:29] <MikeSmith> <CIA-5> * xml/XSLTExtensions.cpp: Added.
- # [12:29] <MikeSmith> <CIA-5> (WebCore::exsltNodeSetFunction): A copy of exslt:node-set() implementation
- # [12:29] <MikeSmith> ]]
- # [12:35] * Quits: MikeSmith (n=MikeSmit@eM60-254-200-76.pool.emobile.ad.jp) (Read error: 104 (Connection reset by peer))
- # [12:44] * Joins: bzed (n=bzed@dslb-084-059-117-215.pools.arcor-ip.net)
- # [12:45] * Quits: Ducki__ (i=Ducki@213-102-101-211.cust.tele2.de) (Read error: 113 (No route to host))
- # [12:45] * Quits: Ducki_ (n=Alex@dialin-145-254-189-028.pools.arcor-ip.net) (Read error: 113 (No route to host))
- # [13:03] <Philip`> jgraham: Okay - I assumed that was probably the case, and added a bug report
- # [13:03] * Philip` needs to fix his OCaml tokeniser so it can help in generating test cases
- # [13:31] <zcorpan_> the forum is getting spam again :(
- # [13:51] <Philip`> Hooray, the OCaml one works
- # [13:52] <Philip`> ...though I don't have any way to test non-PCDATA bits yet
- # [14:05] <Philip`> How should "<!---x-->" get tokenised?
- # [14:05] <Philip`> html5lib gives a comment containing "x", I get one containing "-x"
- # [14:09] <Philip`> "Comment start dash state -> Anything else -> Append a U+002D HYPHEN-MINUS (-) character and the input character to the comment token's data." - looks like html5lib is missing that bit
- # [14:15] <zcorpan_> file a bug
- # [14:17] <Philip`> I was just trying to work out whose bug it was, since I don't trust my own code at all :-)
- # [14:18] <Philip`> but it seems to be theirs, so that's alright
- # [14:35] <jgraham> Philip`: Thanks. It seems I was unsubscribed from the bug tracker email
- # [14:36] * Joins: mpt (n=mpt@121-72-128-43.dsl.telstraclear.net)
- # [14:37] * jgraham wishes the people on public-html would spend their time doing something productive toward the spec or, alternatively, get a hobby that doesn't involve sending me email.
- # [14:41] * Joins: Ducki_ (i=Ducki@dialin-145-254-187-244.pools.arcor-ip.net)
- # [14:45] * Quits: Ducki (i=Alex@nrdh-d9b98030.pool.mediaWays.net) (Read error: 113 (No route to host))
- # [14:50] * Joins: MikeSmith (n=MikeSmit@eM60-254-220-164.pool.emobile.ad.jp)
- # [14:52] * Joins: SavageX (n=maikmert@La62d.l.pppool.de)
- # [14:53] * Quits: maikmerten (n=maikmert@L931f.l.pppool.de) (Read error: 113 (No route to host))
- # [14:57] * Joins: Codler (n=Codler@84-218-7-247.eurobelladsl.telenor.se)
- # [15:12] * krijnh agrees with jgraham
- # [15:12] <krijnh> 636 onread mails :/
- # [15:12] <krijnh> *unread
- # [15:23] <jgraham> Philip`: I think I've fixed both your bugs
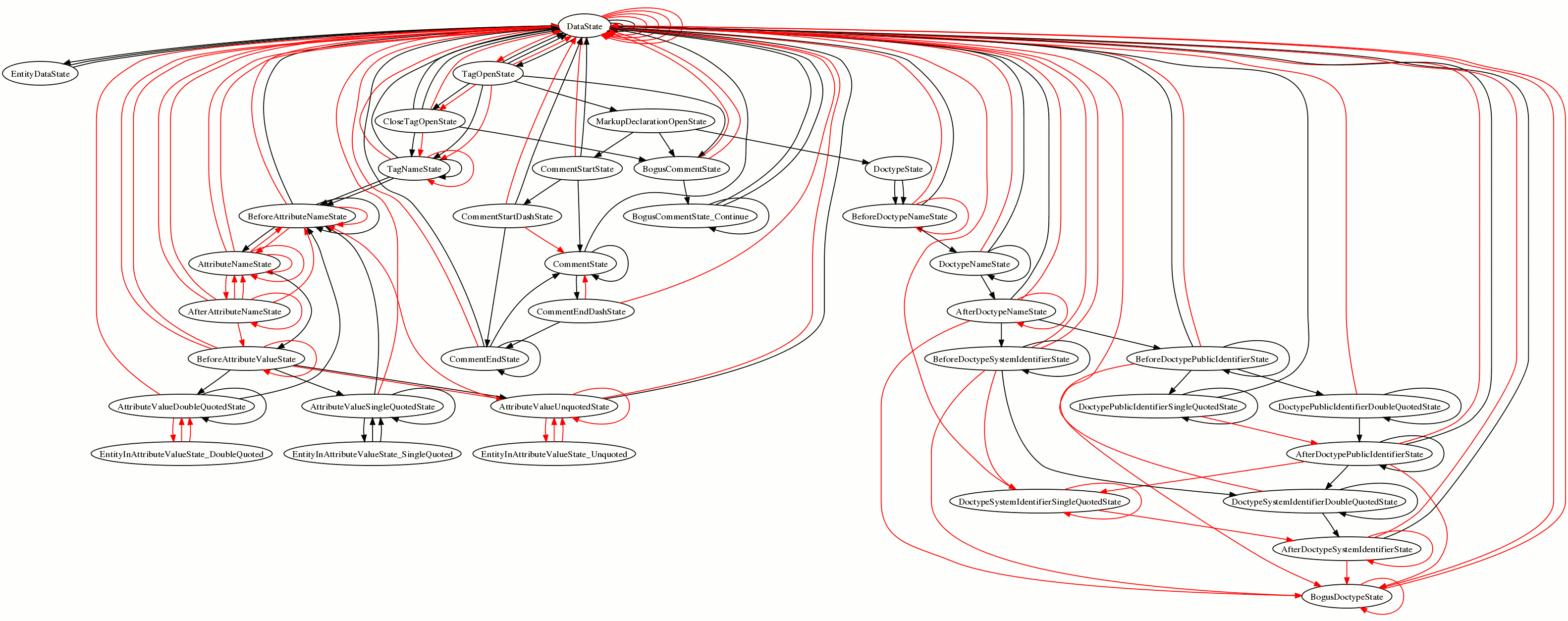
- # [15:28] <Philip`> Unless I did something wrong again, http://canvex.lazyilluminati.com/misc/testcov_html5lib.png should show how much of the tokeniser is covered by the test1.dat, test2.dat from html5lib
- # [15:29] <Philip`> (Each line is one of the algorithm steps from the spec, and black indicates that it's covered by a test)
- # [15:30] <Philip`> (There are a few points where it's definitely wrong, since I haven't implemented named-entity tokenisation yet)
- # [15:31] <Philip`> ((and some of the states with underscores are not really in the spec, they're just slight tweaks to make it fit the state-machine model better))
- # [15:33] <Philip`> Conclusion: more tests needed :-)
- # [15:33] * Quits: mpt (n=mpt@121-72-128-43.dsl.telstraclear.net) (Read error: 104 (Connection reset by peer))
- # [15:53] <gsnedders> the spec references "Unicode character class Z". What is it? I can see nothing about character classes in the unicode spec…
- # [15:53] <Philip`> http://canvex.lazyilluminati.com/misc/testcov_html5.png - frequency of transitions when parsing the HTML5 spec (with line width proportional to log(freq))
- # [15:56] <Philip`> gsnedders: Looks like it's http://unicode.org/Public/UNIDATA/UCD.html#General_Category_Values
- # [15:56] <Philip`> ("Zs: Separator, Space")
- # [15:57] <Philip`> (as the third field in http://unicode.org/Public/UNIDATA/UnicodeData.txt)
- # [16:00] <Philip`> (Maybe HTML5 should say "...characters that are in the Unicode General Category Zs." instead?)
- # [16:00] <gsnedders> "character class" seems to be defined in the first appendix as being a BNF structure (looking it up in the index)
- # [16:13] * Quits: YaaL (i=yaal@hell.pl) (Read error: 104 (Connection reset by peer))
- # [16:14] * Joins: YaaL (i=yaal@hell.pl)
- # [16:29] * Joins: tndH_ (i=Rob@87.102.18.111)
- # [16:30] <Philip`> jgraham: All my tests seem to work in html5lib now - thanks :-)
- # [16:36] * SavageX is now known as maikmerten
- # [16:41] * Joins: Ducki__ (n=Ducki@dialin-145-254-188-212.pools.arcor-ip.net)
- # [16:47] * Quits: tndH (i=Rob@83.100.252.160) (Read error: 110 (Connection timed out))
- # [17:02] * Quits: Ducki_ (i=Ducki@dialin-145-254-187-244.pools.arcor-ip.net) (Read error: 110 (Connection timed out))
- # [18:26] * Quits: Codler (n=Codler@84-218-7-247.eurobelladsl.telenor.se) ("- nbs-irc 2.21 - www.nbs-irc.net -")
- # [18:42] * Joins: Ducki_ (i=Ducki@dialin-145-254-188-129.pools.arcor-ip.net)
- # [18:50] * Quits: Ducki__ (n=Ducki@dialin-145-254-188-212.pools.arcor-ip.net) (Read error: 104 (Connection reset by peer))
- # [19:11] <virtuelv> Hm.
- # [19:11] <virtuelv> <section><header><h1>...</h1></header><nav></nav></section> produces a rather broken DOM in Firefox
- # [19:20] <Philip`> You could write XHTML5 and then it'd give the right DOM :-)
- # [19:22] <virtuelv> Heh. As if
- # [19:23] <zcorpan_> as if what?
- # [19:23] <zcorpan_> You could write XHTML5 or it'd give the right DOM?
- # [19:24] <virtuelv> as if I'll ever serve something with application/*
- # [19:24] <zcorpan_> so the former :)
- # [19:24] <Philip`> You could write HTML5, and then just use some translation layer on the server to provide XHTML5 to legacy user agents for backward compatibility
- # [19:24] <virtuelv> well, in one word, no.
- # [19:24] <Philip`> though then you'd need something else for legacy legacy UAs like IE7
- # [19:24] <virtuelv> I'd rather give Firefox users unstyled content
- # [19:25] * Joins: h3h (n=w3rd@cpe-76-88-44-219.san.res.rr.com)
- # [19:26] <zcorpan_> header+h1
- # [19:26] <zcorpan_> :P
- # [19:36] * Quits: virtuelv (n=virtuelv@pat-tdc.opera.com) ("Leaving")
- # [19:43] * Joins: ROBOd2 (n=robod@86.34.246.154)
- # [19:54] * Quits: ROBOd (n=robod@86.34.246.154) (Read error: 110 (Connection timed out))
- # [20:19] * Joins: virtuelv (n=virtuelv@pat-tdc.opera.com)
- # [20:25] * Joins: csarven (n=nevrasc@modemcable081.152-201-24.mc.videotron.ca)
- # [20:38] * Quits: minerale (i=achille@about/cooking/alfredo/Minerale) (Read error: 113 (No route to host))
- # [20:42] * Joins: Ducki (i=Ducki@dialin-212-144-055-072.pools.arcor-ip.net)
- # [21:00] * Quits: Ducki_ (i=Ducki@dialin-145-254-188-129.pools.arcor-ip.net) (Read error: 113 (No route to host))
- # [21:05] * Joins: dev0 (i=Tobias@unaffiliated/icefox0)
- # [21:13] * Joins: billyjack (n=MikeSmit@eM60-254-199-114.pool.emobile.ad.jp)
- # [21:15] * Quits: MikeSmith (n=MikeSmit@eM60-254-220-164.pool.emobile.ad.jp) (Read error: 110 (Connection timed out))
- # [21:41] * Joins: weinig (i=weinig@nat/apple/x-25b264972ae92bc5)
- # [22:05] * Quits: ROBOd2 (n=robod@86.34.246.154) ("http://www.robodesign.ro")
- # [22:05] * Quits: h3h (n=w3rd@cpe-76-88-44-219.san.res.rr.com)
- # [22:09] <hsivonen> when the list of formatting elements is cleared up to a marker, does the rest of the algorithm guarantee that there is a marker?
- # [22:17] * Joins: dbaron (n=dbaron@c-71-198-189-81.hsd1.ca.comcast.net)
- # [22:34] <Philip`> I can [I think] guarantee that the current token in the tokeniser is always the correct type (e.g. it's a tag token if you're appending to the tag token name, and it's a tag token with attributes if you're appending to the attribute name, etc), but I know nothing at all about the tree construction
- # [22:35] <Philip`> but I'd really like to look at that at some point and see if it's similarly straightforward to prove things about it, since it's nice when it works :-)
- # [22:35] <hsivonen> ok
- # [22:35] <hsivonen> yeah, it would certainly be nice if the algorithm was proven correct
- # [22:36] <hsivonen> and then if my optimizations are correct :-)
- # [22:37] <hsivonen> in many places, as written, the algorithm involves searching the stack twice or thrice per token even though searching once and remembering the stack slot found would be enough as the operations in between don't alter the slot
- # [22:38] <Philip`> The main difficulty I have is in convincing myself that my proof method is correct
- # [22:38] <Philip`> I guess I should find some way to make the prover output easily-verifiable conditions, so people can check the proof was valid
- # [22:42] * Joins: Ducki_ (n=Ducki@dialin-145-254-186-204.pools.arcor-ip.net)
- # [22:48] * Quits: maikmerten (n=maikmert@La62d.l.pppool.de) ("night")
- # [22:55] * Quits: Toolskyn (i=toolskyn@amy.bdick.de) (Remote closed the connection)
- # [23:02] * Quits: Ducki (i=Ducki@dialin-212-144-055-072.pools.arcor-ip.net) (Read error: 113 (No route to host))
- # [23:37] * Joins: Ducki (i=Ducki@dialin-145-254-188-106.pools.arcor-ip.net)
- # [23:42] * Quits: dbaron (n=dbaron@c-71-198-189-81.hsd1.ca.comcast.net) ("8403864 bytes have been tenured, next gc will be global.")
- # Session Close: Sun Jul 08 00:00:00 2007
The end :)
{kind=link}
{kind=link}